Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
公式ルールと始め方ガイド
このセクションの記事は次の通りです:
A.セキュリティ上の理由から、NumeraiはMFAで保護されたアカウントを回復することはありません。 これは、他人があなたのアカウントを乗っ取ることを防ぐためです。 Numerai運営がアカウントの回復をしないことは、ユーザーにとってよくないことは認識していますが、 大量の NMRを保持する関係上、セキュリティを何よりも優先する必要があります。
MFA を設定するときは、回復コードを書き留めて、安全な場所に保存してください。 これらの回復コードを使用すると、MFAデバイスにアクセスできなくなった場合でも、アカウントを回復できます。 Numeraiへのログイン時に、MFAの入力を求められたら、リカバリコードを入力すれば大丈夫です。 一部のユーザーは、MFA をまったく有効にしていません。アカウントのセキュリティが低下するため、MFAを設定した方がよいです。
A.Richard Craib(Numeraiの創設者)は、世界の株式市場のデータを表していると述べています。
A.Numeraiはトーナメントの完全性を維持するために、データに関する情報を意図的に公開していません。 さらに、ヘッジファンドの品質データを無料で提供するためには、データを暗号化して難読化する必要があります。 参加者に多くの情報を提供するとバイアスが生じるだけで提出された予測の品質が低下する可能性があります。
A.Numeraiは仮想通貨の取引を行っていません。また、ユーザーは仮想通貨の価格を予測することは求められていません。
A.いいえ。NMRはERC20ユーティリティトークンです。https://www.cryptoratingcouncil.com/asset-ratings 適切な機関投資家および認定投資家のみが、ヘッジファンドに資金を割り当てることができます。トーナメント運営とNumeraireはヘッジファンドとは別の事業体です。
A.NMRを予測に賭けることで、トーナメント参加者とNumerai間の情報の非対称性の一部が取り除かれます。 ユーザーは予測に賭けることで、モデルの品質について「コストのかかるシグナル」を提供しています(、1973)。 (つまり、NMRをユーザーが賭けることで、提出したモデルに自信があることを表明することとなります) ステーキングにはリスクが伴いますが、良好なパフォーマンスを得るために NMR で報酬が渡されます。
A.はい! NMR は、脆弱性の報告、Numerox などのオープンソースパッケージの作成または貢献、技術資料のさまざまな言語への翻訳、およびチームが提供するその他の機会によって獲得できます。
A.予測ファイルに括弧、パーセント記号、またはスペースが含まれている場合、提出は失敗します。すべての特殊文字を削除して、再試行してください。 手間を省きたい場合は numer.ai/submit にアクセスしてください。 サンプルコードが記載されており、API を利用して提出することができます。さらに技術サポートが必要な場合は、https://community.numer.aiまでお問い合わせください。
A.コンピューターをホットスポットに接続してみてください。一部の小規模なインターネットサービスプロバイダーは、提出物を保存するS3へのアップロードをブロックしています。
A.前のラウンドの予測をアップロードしようとしている可能性があります。データセットを再度ダウンロードして、最新のトーナメント データを使用していることを確認してください。 最新のトーナメントデータでモデルを再実行すると、このエラーメッセージが再び表示されることはありません。
A.RocketChatに参加し、#newusersチャンネルにアクセスしてください。 質問をしてしばらく待てば誰かが解答してくれます。
A.Numeraiは世界で最も難しいパズルの一つです。 検証データで高いCorrを持つモデルは、ライブデータのトーナメントでパフォーマンスを発揮するかわかりません。 最善の行動は、生成された予測が安定かを確かめるために、毎週トーナメントに提出することです。 Numerai-CLIを使用してプロセスを自動化することで、時間どおりに提出することを心配する必要がなくなります。 モデルが他のユーザーと比較してどのように機能するかを観察し、自分のモデルに自信が持てるようになったら、NMR を賭けるとよいでしょう。
A.Numeraire は分散型の ERC20 トークンです。を実行することができます。スマートコントラクトの歴史についてはをお読みください。
手順的には以下の通り
予測のランク値化および平均値を0に変換
予測値とターゲット両方を1.5乗
... ヘッジファンドは予測リターンが最も高いか低い銘柄のみを取引する傾向があるため、テールを強調するためにこのような処理を行います。
ピアソン相関係数を計算
1.でランク化を行っているため、スピアマン相関係数に近いものの、2.の1.5乗の処理により典型的な順位相関よりもテールに依存します。
ウェブサイトでは、CORR のさまざまなバリエーションを見ることができます。
CORR20V2 - メインターゲットの20日バージョンに対する最新の相関係数のスコア。
CORJ60 - Jeromeという補助ターゲットの60日バージョンに対する相関性
import numpy as np
from scipy import stats
def numerai_corr(preds, target):
# rank (keeping ties) then Gaussianize predictions to standardize prediction distributions
ranked_preds = (preds.rank(method="average").values - 0.5) / preds.count()
gauss_ranked_preds = stats.norm.ppf(ranked_preds)
# make targets centered around 0
centered_target = target - target.mean()
# raise both preds and target to the power of 1.5 to accentuate the tails
preds_p15 = np.sign(gauss_ranked_preds) * np.abs(gauss_ranked_preds) ** 1.5
target_p15 = np.sign(centered_target) * np.abs(centered_target) ** 1.5
# finally return the Pearson correlation
return np.corrcoef(preds_p15, target_p15)[0, 1]Numerai Tournament用のサンプルスクリプト こちらは、Numeraiのデータをダウンロードした際に含まれる機械学習スクリプトの例です。 Numerai Tournamentファイルのデータ分析と情報 Tournamentファイルのデータがどのような傾向を示しているか分析するツールです。特徴量の作成や機械学習モデルの作成に役立つかもしれません。 その他のツール 英語版のツールに関するリンク集です。
本ライブラリは、Numerai APIへのPythonクライアントです。インターフェースはPythonでプログラムされており、トレーニングデータのダウンロード、予測値のアップロード、ユーザー、submission、competition情報へのアクセスが可能です。 これは、メインcompetitionと新しいNumerai Signals competitionの両方で動作します。 本インターフェースは、Tournamentデータのダウンロード、予測の提出、ユーザー情報の取得、NMRの預け入れなどを行うことができます。 R言語を用いて関数を使用すると、参加者はNumerai Tournamentに関連する全ての手続きを自動化することができます。
クラウド上で完全自動化された予測ファイルの提出ワークフローを1ドル/月未満でできるツールです。 Numerai Tournamentに自動的に参加できるPythonデーモンです。
Numeraiとそのコミュニティから、多くのチュートリアルモデルが提供されています。
Numeraiの基本的な例のモデルはGithubで見つけることができます。
Jason Rosenfeld(jrAI)は、Numerai Signals用のエンドツーエンドのノートブックを作成しました。Yahoo Financeの無料データを使ってデータセットを作成し、簡単なモデルをトレーニングします。Google Colabで確認でき、このビデオでも紹介されています。
データソースのリストはで確認できます。
ターゲット
タイムライン: 20D2L(土日を除いた20日(土日を含めて28日)のリターン、2日のラグ)
ビン=5、均一性=10%、40%、50%(0と1が5%ずつ、0.25と0.75が20%ずつ、0.5が50%)
Numerai Cryptoの提出物は、まず次のようにクリーンアップされます:
トークンユニバースで結合
NaN値と重複するシンボルを削除
各提出物をランク化(タイ値はキープ)
各提出物のNaNを0.5で埋める
次に、少なくとも1 NMRステークがあるクリーンなCrypto提出物の平均からメタモデル(CNWMMmin1; Numerai Crypto Naive-Weighted Meta Model w/ minimum 1 NMR stake)が計算されます。
submissionされた予測値はスコアリングに使用される前にクリーンアップされます:
・無効なシンボルを削除
・提出物をランク化(タイ値はキープ)
・NaNを0.5で埋める
MMC(Meta Model Contribution)の計算方法
・Submissionされた予測値、CNWMMmin1、ターゲットの相関からMMCが計算されます
・タイムライン: 20D2L(土日を除いた20日(土日を含めて28日)のリターン、2日のラグ+2日のデータのラグ)
CORR(Correlation)の計算方法
・submissionされた予測値とターゲットのNumerai相関から計算されます。
・タイムライン: 20D2L(土日を除いた20日(土日を含めて28日)のリターン、2日のラグ+2日のデータのラグ)
Numerai Cryptoには1つのターゲットがあり、それは30日後のトークンのリターンです。各ラウンドごとに、ユニバース内の各トークンの30日間のリターンはランク付けされ、ガウス化された後、5つのビンに分けられます。
Numerai Cryptoのデータセットにアクセスする最良の方法はデータAPIを使用することです:
train_targets.parquet には過去のシンボルとターゲットが含まれています。
live_universe.parquet には現在のラウンドのターゲットがない最新のトークンユニバースが含まれています。
from numerapi import NumerAPI
napi = NumerAPI()
[f for f in napi.list_datasets() if f.startswith("crypto/v1.0")]
[
'crypto/v1.0/live_universe.parquet',
'crypto/v1.0/train_targets.parquet',
]
# トレーニングデータをダウンロード
napi.download_dataset("crypto/v1.0/train_targets.parquet")blog_ukiによるNumerai Signalsの紹介
Jason Rosenfeld(jrAI)によるYahooFinanceの完全無料データを使用したNumerai Signalsのノートブック。
Jason Rosenfeldによるノートブック
SurajParmarによる記事とノート
データとツールのアイデアに関するフォーラムスレッド
公式ルールと始め方ガイド
前書き
Numerai Tournamentとは、株式市場の動向を予測し、競争するプラットフォームです。 参加者は難読化されたデータを使用して機械学習モデルを構築し、予測ファイルを提出することでTournamentに参加できます。 また、提出した予測ファイルにNMRと呼ばれる暗号通貨を賭けると、パフォーマンスに基づいてNMRを獲得できます。 Numeraiに提出された予測ファイルは、Numeraiが保有するヘッジファンドのモデル(メタモデル)を設計するために使用されます。下に示すyoutubeを見ることで、どのようにデータが使用されるか学べます。
概要
1.Numeraiにする。 2.トレーニングデータとサンプルスクリプトを含むデータセットをダウンロードする。 3.モデルを作成し、予測をNumeraiに送信する。 4.モデルにNMRを賭けて、パフォーマンスに基づいてNMRを貰う/払う 6.毎週の提出物を自動化する。
Numerai Tournamentの中核は無料のデータセットが使用できることです。データセットはクリーンアップ・正規化・難読化された高品質の財務データで構成されています。
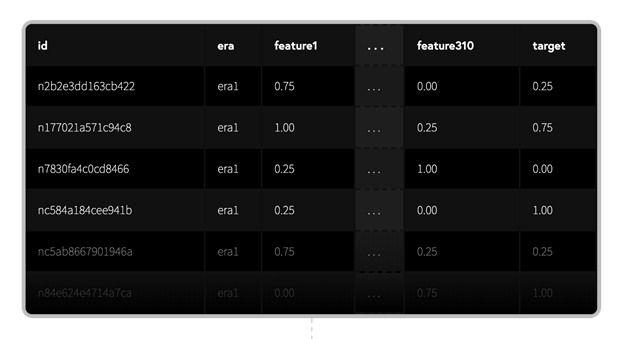
提供されているtraining_dataでは、各idは難読化されたfeaturesのセットを持つ株式に対応しています。
targetは将来のパフォーマンスを表します。行は、異なる時点を表すerasにグループ化されています。
詳細はに詳しく記述されています。
Numerai Tournamentでは、過去のデータを用いて予測モデルを作成し、そのモデルを用いて将来の株式市場を予測することが目的です。 PythonでXGBoostを使用した基本的な例を次に示します。 過去のトレーニングデータを使用してモデルをトレーニングし、ライブTournamentデータで予測を行います。 (*本プログラムのみでは予測ファイルの提出ができません。より実践的な例はをチェックしてください。
毎週土曜日の18:00 UTC(日本時間では日曜日03:00 JST) に新しいラウンドが始まり、新しいTournamentデータが公開されます。Tournamentデータを用いて予測値の入ったファイルを作成し、Numeraiに提出しましょう!
締め切りは月曜日14:30 UTC (日本時間では月曜日23:30 JST) です。提出が遅れた場合、ペイアウトの対象外となります。
やGraphQL を使用することもできます。
以下は、コードの例です。
また、 を用いて毎週の予測ファイル提出を自動化することもできます。
モデルパフォーマンスはDIAGNOSTICSに示される指標を用いて診断することができます。過去のデータから提出した予測ファイルのパフォーマンス・リスクを評価する指標が表示されます。
詳細についてはこのを読んでください。
あなたが提出した予測結果は、あなたの予測と真のターゲットの correlation (ここではspearmanの順位相関)でスコアリングされます。相関性が高いほど高いペイアウトを得られます。
予測結果は、メタモデルへの寄与(TC)と機能の中立的な相関(fnc)についてもスコアが付けられます。
各提出物は、Tournamentが開始してから4週間にわたって評価されます。締め切り後の木曜日に最初の評価を受け取り、4週間後の水曜日に最終スコアを受け取ることができます。合計で20スコアの加重平均値がペイアウトされるNMRの量を決定します。
Tournamentが終了するまでには約4週間かかるため、毎週新しい予測ファイルを提出すると、進行中の4つのラウンドから各スコアリング日に複数(最大4)の評価を受け取ります。
モデルのライブスコアは、プロフィールページで公開されています。これは、過去20ラウンドにわたるモデルの最終スコアの例です。
特定のラウンドにズームインして、ラウンド内の毎日のスコアを確認することもできます。
などのNumeraiにとって不都合な攻撃を防止しつつNMRをペイアウトするにはどのようなシステムを設計すればよいでしょうか? その答えはステーキング(=預け入れ)です。各参加者はNMRを掛け金として自分の予測の正確さを担保します。NMRのステーク量が多ければ多いほど予測に自信をもっているとみなします。 Numeraiは正確な予測ファイルの提出を望んでおり、良い予測には高い報酬で報います。 どれだけのNMRを得られるかはNMRのステーク量と、Corr、TCの値に依存します。 これは、という本で述べられているメゾットを使用しています。 NumeraiにNMRをステーキングする場合、Numeraiはシビル耐性のある方法を提供します。NMRのペイアウトはステーク量に比例するため、複数のアカウントを作成するだけでは多くのペイアウト得ることができません。 もちろん、NMRをステークせずにNumeraiに参加することもできます。 例えば、Tournamentの詳細や自分のモデルの性能を知るために、NMRをステークしないのは良いテストとなるでしょう。 自分のモデルに自信が持てるようになったら、そのモデルにステークすることができます。ステークの最小値は3NMRです。
Numeraiのウェブサイトでは、「Manage Stake」をクリックしてステーク量を管理できます。このモーダルを使用すれば、NMRのステーク量を増減したり、ベットする指標の変更ができます。 ステーキングとは、NMRをイーサリアムブロックチェーンのスマートコントラクトに固定することを意味します。ステーク中はNumeraiがロックアップされたNMRを増減させる権利を保有します。
NMRのステーク量を増やすと、あなたのウォレットからNMRが引き出され、Numeraiの保有しているアカウントにNMRが移送されます。 NMRのステーク量を減らすと、Numeraiの保有しているアカウントからNMRが移送され、あなたのウォレットに入金されます。
ステーク量への変更はすぐに適用されるのではなく、約4週間後に反映されます。これは、Tournamentの終了期間が4週間であることに起因します。
どれだけのNMRを得られるかはNMRのステーク量と、Corr、TCの値に依存します。
スコアが高いほど、より多くのNMRを得ることができます。もし負のCorr、TCとなった場合、ステークしたNMRの一部が没収され、バーンされます。
バーンとはERC-20トークンの持つ機能の一つであり、トークンを永遠に使用できなくする操作のことです。
ペイアウトされるNMRの量はステークした量の±25%に制限されています。
ペイアウトは以下の式で計算されます。
payout = stake_value * payout_factor * (corr * corr_multiplier + mmc * mmc_multiplier)
stake_value:ラウンド開始時点の最初の木曜日にステークしたNMRの量
payout_factor:30万NMR以下では1、30万NMR以上では以下の図に示す値をとります。Numeraiはペイアウトの上限を決めることで持続的なTournamentの開催を行うことができます。
corr:提出した予測ファイルとターゲットの相関
corr_multiplier:現在は1のみ
tc:提出した予測ファイルが最終的なポートフォリオのリターンへどのくらい貢献しているか
tc_multiplier:0, 0.5, 1, 1.5, 2, 2.5, 3の中で一つ選べる。
ペイアウトファクターの関数やマルチプライヤーは、Numeraiによって変更される可能性があります。
ペイアウト計算の例を下図に示します。
最初の2つの例は、corr_multiplierの影響を示しています。
3番目の例は、負のスコアがペイアウトに影響を与えるかを示しています。
4番目の例は、ペイアウトがステーク量の±25%に制限されていることを示しています。
スコアは毎日更新されますが、ペイアウトはTournamentの終了日(日本時間の木曜日)にのみ行われます。参加者の一人が作成したNumeraiPayoutsアプリを使用すると、毎日の変化を追跡できます。 ステークを開始すると、最初の4ラウンドの間ステーク値は一定に保たれます。その後、4週間前のラウンドの支払いに基づいて、ステーク値が毎週更新されます。
提出した予測ファイルがプラスのスコアを持ち続ける限り、得られたNMRの量は増大します。モデルが52週間、毎週同じ正のスコアを取得すると仮定した場合の支払い予測の例を下図に示します。
Numeraiは、積極的にペイアウトルールを悪用している、または悪用していると判断した場合には、賭け金を払い戻し、すべての得られたNMRを無効化にする権利を保有します。
Numeraiの支払いシステムは攻撃に強いように設計されています。ユーザーが罰を恐れずに新しいアイデアを試してもらいたいため、この権利を行使することはめったにありません。
悪質な攻撃を発見した場合には、そのことをコミュニティに伝えてください。以前あった攻撃の一つがで紹介されています。
NMRのペイアウトはラウンドごとのパフォーマンスに左右されます。リーダーボードに掲載される評価や順位は20ラウンド分のCorr,TCの加重平均値を用いています。 詳しくは、 のセクションを参照してください。
助けが必要ですか?
質問、サポート、フィードバックは にお願いします!
Numerai データセットは、世界の株式市場を時系列に記述した表形式のデータセットです。
Eraは日付を表し、idは銘柄と各Eraが匿名化されたIDである。特徴量はその時点で判明している銘柄の属性(例えばPER)を表し、targetはその時点に対する将来のリターン(20日後/60日後)を表す。
データセットには、PERのようなファンダメンタルズから、RSIのようなテクニカルシグナル、空売りのようなマーケットデータ、アナリストの格付けのようなセカンダリーデータなど、多くの特徴があります。
各特徴はNumeraiによって綿密に設計され、ターゲットの予測に役立つように、あるいは他の特徴との相乗効果が得られるように設計されています。リーク問題を回避するため、すべての特徴量がその地点のデータを表すよう細心の注意を払っています。
多くの特徴はそれ自体でターゲットを予測することができますが、その予測力は時間の経過とともに一貫性を欠くことが知られています。
そのため、少数の特徴に依存しすぎたり、相関性の高いモデルを構築することは、パフォーマンスに一貫性がなくなる可能性が高いため、お勧めしません。詳しくはをご覧ください。
注:いくつかの特徴値はNaNになる可能性があります。これは、その時点では利用できない特徴データがあるためです。
データセットのターゲットは、ヘッジファンドの戦略に合うように特別に設計されています。
我々のヘッジファンドが市場/国/セクター、ファクター・ニュートラルであることから、基本的にターゲットは市場/国/セクターの広範なトレンドやよく知られたファクターでは説明できない銘柄固有のリターンと解釈できます。簡単に言えば、私たちが求めているのは「アルファ」なのです。
メインターゲットとは別に、私たちは様々なタイプの株式固有のリターンである多くの補助ターゲットを提供しています。メインターゲットと同様に、これらの補助ターゲットも銘柄固有のリターンに基づいていますが、残差化されるもの(例:市場/国対セクター/ファクター)や時間軸(例:20日/60日)が異なります。
我々の目的はメインターゲットを予測することですが、これらの補助的なターゲットもモデル化することが有用であることが分かっています。時には、補助ターゲットで学習したモデルがメインターゲットで学習したモデルを上回ることもあります。他のシナリオでは、異なるターゲットで訓練されたモデルのアンサンブルを構築することもパフォーマンスに役立つことがわかりました。
注意:補助ターゲットの値がNaNになることはありますが、メインターゲットがNaNになることはない。これは、あるターゲット・データがその時点では利用できないためで、偽の値を作る代わりに、それをどのように扱うかを自分で選択できるようにしています。
Erasは異なる時点を表し、特徴値はその時点のものであり、Targetはその時点より未来の値です。
各行を1つのデータポイントとして扱うのではなく、各Eraを1つのデータポイントとして扱うことを強く考慮すべきである。これと同じ理由で、Numeraiの指標の多くは「Eraごと」に計算されています。例えば、Numeraiで使われているCorrはEraごとの平均値が用いられています。
ヒストリカルデータ(トレーニング、検証)では、各時代の間隔は1週間ですが、目標値は20日または60日先読みすることができます。これは目標値が「重複」していることを意味するので、クロスバリデーションを適用する際には特別な注意が必要です。詳しくはを参照のこと。
ライブデータでは、各新ラウンドに新たなEraのライブ特徴量が含まれるが、その間隔はわずか1日です。
Numeraiデータセットにアクセスする最良の方法は、データAPIを利用することです。
Numeraiデータセットは多くの異なるファイルで構成されています。
ここでは、どのファイルが利用可能か、どのようにファイルをダウンロードするかを確認するために、データAPIに問い合わせる方法を説明します。
train.parquet には、特徴とターゲットを含む、学習用のデータが含まれています。
validation.parquet には、特徴量とターゲットを含む、評価用のデータが含まれます。
live.parquetには、現在のラウンドのターゲットなしの最新のライブ特徴量が含まれます。
Numeraiデータセットは、常にアップデートのあるデータセットです。一般的に、新しいモデルを構築する場合は、最新バージョンを使用することが推奨されます。
から最新のデータを確認してください。
NMRを自分のモデルにステーク(賭ける)ことで、CorrとMMCスコアに基づいてNMRを稼ぐか失うことができます。ステーキングとは、NMRをEthereumブロックチェーン上のNumeraiウォレットにロックすることを意味します。ステークの期間中、NumeraiはロックされたNMRに対して支払いを追加したり、焼却したりする権限を持っています。
ステークはウェブサイトで管理できます。ステークを増やすと、NMRがウォレットからステーキングに移されます。ステークを減らすと、約4週間の遅延の後、NMRがステーキング契約からウォレットに戻されます。
ペイアウトは、ステークの価値とスコアに依存します。ステークの価値が高く、スコアが高いほど、より多くの報酬を得ることができます。スコアがマイナスの場合、ステークの一部が焼却されます。ペイアウトは、ラウンドごとにステーク価値の±5%に制限されています。
stake_value はラウンド終了時点でのステークの価値(および未決済のリリースを引いた値)であり、提出がない場合は0です。
payout_factor は、ステーク全体のNMRが stake_cap_threshold を超えて増加するにつれて、対数的に減少します。
2024/08/31段階で、Numerai Cryptoの stake_cap_threshold は10,000です。
Discord(日本) 有志が運営する日本語版のチャットルーム
Discord(公式) Numerai公式が運営する英語版のチャットルーム
Forum NumeraiやSignalsについて議論するスペース。
Numerai公式が運営するTwitter アカウント
Numerai公式が運営するblog
Numerai公式が運営するSubreddit
email: [email protected]
あなたのシグナルが十分に低いチャーン率を持っている場合、モデルにNMRをステーキングして、FNCV4およびMMCスコアに基づき報酬を得たり、焼却されたりすることができます。
ステーキングとは、Ethereumブロックチェーン上のスマートコントラクトにNMRをロックすることを指します。ステーキング期間中、NumeraiはロックされたNMRに対して報酬の追加や焼却を行う権限を持ちます。
ウェブサイト上でステーキングを管理することができます。ステーキングを増やす場合、NMRはウォレットからステーキングコントラクトに転送され、減らす場合は約4週間の遅延後にコントラクトからウォレットにNMRが戻されます。また、どのスコアに対してステーキングするかを選ぶステーキングタイプも変更可能です。
報酬はステーク価値とスコアの関数で決まります。ステーク価値が高く、スコアが高いほど、より多くの報酬を得ることができます。スコアがマイナスの場合、ステークの一部が焼却されます。報酬は1ラウンドあたりステーク価値の±5%に制限されています。
stake_valueはラウンドのclose時のステーク価値(保留中のリリースを除く)で、提出がない場合は0となります。
payout_factorは、総ステーキングNMRがstake_cap_thresholdを超えると対数的に減少します。stake_cap_thresholdの値についてはをご参照ください。
シグナル作成に使用される基礎データは非常に多様です(監査済み財務情報、ニュース記事、駐車場の画像など)。ただし、すべてのシグナル提出は同じ基本形式、つまり、株式ティッカーのリストと、それぞれに0から1の範囲の数値が関連付けられている必要があります。
提出内の株式ティッカーのリストは、Numerai Signalsの株式市場ユニバースによって定義されます。このユニバースには、世界で最大規模の約5000銘柄が含まれており、毎日更新されます。一般的に、日ごとに流動性の低い銘柄がわずかに入れ替わります。
最新のユニバースは、から確認してください。
シグナルを提出する際には、少なくとも以下の2つの列を含める必要があります:
features.json には、特徴量と特徴量セットに関するメタデータが含まれます。
meta_model.parquet には、過去のラウンドのメタモデル予測が含まれます。
live_example_preds.parquet には、サンプルモデルの最新のライブ予測が含まれます。
validation_example_preds.parquet には、サンプルモデルの検証予測値が格納されています。
payout = stake_value * payout_factor * (corr * 1 + mmc * 2)
「ゲームに参加する」ことによって、NumeraiはStakeされた予測の質を信頼することができます。
ペイアウトとバーンは継続的にメタモデルのウェイトを向上させます。
NumeraiのStaking に向かい、「manage stake」ボタンをクリックして賭け金モーダルを開きます。
賭けフォームを使って、お客様のウォレットからNMRをモデルに賭けましょう。
ペイアウトを計算するために使用されるスコア倍率と、収益の行き先をオプションで設定することができます。
ペイアウトは主にスコアによって決まります。スコアがプラスの場合、ペイアウトを受け取ることができます。マイナススコアの場合、賭け金の一部が燃やされます。
ラウンドあたりの最大ペイアウトまたはバーンは±5%が上限となります。
stake は、ラウンド終了時のモデルの賭け金です。これは、ラウンドのリスク時の賭け金とも呼ばれます。また、ラウンドに有効なサブミッションがない場合は0に設定されます。
payout_factor は動的な値で、staking_thresholdに基づいて賭けられたNMRの合計に反比例します。
Numerai tournament
72000
Numerai signals
36000
Corrの倍率とTCの倍率は、各スコアへのエクスポージャーを制御するためにあなたが設定します。以下はそのオプションです。
0x, 0.5x, 1.0x, 1.5x, 2.0x
0x, 0.5x, 1.0x
※:ラウンド589の時点で、TCにStakeするためには、2.0xCorrにStakeする必要があります。
Numeraire(NMR)は、Numeraiのステーキングとペイアウトの原動力となる暗号通貨です。
あなたのモデルにNMRをStakeするには、あなたのアカウントの固有の入金アドレスでNumeraiウォレットにNMRを入金する必要があります。
cusip、sedol、bloomberg_ticker、composite_figi、または numerai_ticker の列 - ヘッダーで指定したティッカータイプに対応する有効なティッカーである必要があります。
signal 列 - 値は0から1の範囲(0と1は含まない)である必要があります。
さらに、live提出が有効であるためには、以下の条件も満たす必要があります:
ユニバース内の少なくとも100銘柄に対して有効な値(0から1の範囲)が含まれていること。
現在のlive期間内に同じティッカーが複数回含まれていないこと。
APIを使用して提出ワークフローを自動化できます。予測結果を含むCSVを生成した後、以下のように提出を行います:
次のいずれかの方法を使用できます:
Numerapi(公式Pythonクライアント)
RNumerai(非公式Rクライアント)
他の言語向けの生のGraphQL API

from numerapi import NumerAPI
napi = NumerAPI()
napi.list_datasets()
# => ['v5.0/features.json',
# 'v5.0/live.parquet',
# 'v5.0/live_benchmark_models.parquet',
# 'v5.0/live_example_preds.csv',
# 'v5.0/live_example_preds.parquet',
# 'v5.0/meta_model.parquet',
# 'v5.0/train.parquet',
# 'v5.0/train_benchmark_models.parquet',
# 'v5.0/validation.parquet',
# 'v5.0/validation_benchmark_models.parquet',
# 'v5.0/validation_example_preds.csv',
# 'v5.0/validation_example_preds.parquet']
# Download the training data
napi.download_dataset("v5.0/live.parquet")payout = stake_value * payout_factor * (fncv4 * 1 + mmc * 2)payout = stake * clip(payout_factor * (corr * corr_mult + tc * tc_mult), -0.05, 0.05) payout_factor = min(1, stake_threshold / total_at_risk)from numerapi import SignalsAPI
# 認証
sapi = SignalsAPI("[your api public id]", "[your api secret key]")
sapi.upload_predictions("[path to your submission].csv")
Numeraiの改善提案をすることで報酬がもらえます
バグ・重大な問題を発見した場合、発見者にNMRを報酬として与える仕組みが用意されています! 以下に記載されている報酬は目安であり、正確な金額は、バグ、フィードバック、提案によって異なります。
私たちはNumeraiを改善するために、有用な提案に対して報酬を与えます。もし、報酬額に問題があると感じた場合は、遠慮なくお知らせください。
ウェブサイトやNumeraiの仕組みにバグを見つけたら報告してください! バグの例を以下に示します。
注: 報酬の支払いを受けるには、のアカウントが必要です。600ドル以上の賞金を受け取る米国人は、を提出する必要があります。
バグに関する調査中は、以下のことはご遠慮ください。
サービス拒否
スパム
あらゆる種類の自動スキャン
セキュリティヘッダーの欠落 (eg. HSTS, CSP)
# でメッセージを送っていただければ、Numerai運営が対応します。
レポートにはバグによってどのような問題が起きているかを含めてください。必要ならユーザー名などの詳細な情報も記入してください。 また、エラーを再現する方法やスクリーンショット、エラーメッセージも含めてください。
問題がウェブサイトにある場合は、お使いのブラウザとインストールされている拡張機能(アンチウイルス、広告ブロック)に関する情報を含めてください。この情報を公開することに抵抗がある場合は、ダイレクトメッセージを送信するか、[email protected] まで電子メールを送信してください。
もしあなたがNumeraiを改善するための良いアイデアをお持ちでしたら提案してください! もしそれが良いアイデアであり、Numeraiが採用した場合は、報酬を差し上げます!
# でメッセージを送ってください。
多額の報酬を狙うのであれば、アイデアを文書(pdfやgoogle docs)やノート(google colab、github)に書き出してくれると助かります。
Numerai Signalsデータセットは、時間の経過に伴う世界株式市場を記述した表形式のデータセットです。
概略として、各行は特定の時点での株式を表し、numerai_tickerまたはcomposite_figiと日付によって識別されます。日付は、マーケットクローズのデータが特徴量生成に使用された日を示し、ラウンドやライブデータのコンテキストではラウンドが始まる前日を指します。ターゲットは、その日付からの将来のリターン(例:20日後)の指標です。
Signalsデータセットには以下が含まれます:
ファクター: ターゲットが中立であるファクターに類似したもので、モデルの独自性の判断、予測の中立化、またはデータセットの追加特徴量として使用できます。
スタータ特徴量: 比較的単純なクラシックなクオンツ指標で、リターン系列から構成されています。
データセットの特徴量は以下のとおりです:
名前に{n}(d|w)が含まれる特徴量(例:feature_adv_20d_factor)は、n日またはn週間の期間で計算される時系列の特徴量です。 名前にcountry_ranknormが含まれる特徴量は、国ごとにグループ化された後、ランク付けされ、正規化されています。 factorを含む特徴量は、多くのターゲットが中立であるリスクファクターを指します。価格ファクターは国ごとにグループ化され、ランク付けされています。 PPOは、短期と長期の移動平均を比較するパーセンテージ価格オシレーターです。 RSIは、買われ過ぎ・売られ過ぎの指標として使用される相対力指数です。 TRIXは、モメンタムまたは反転指標として使用されるトリプル指数移動平均インジケーターです。 momentum_52w_less_4wは、直近4週間を除いた1年間の株式のリターンを指します。
データセットのターゲットはヘッジファンドの戦略に適合するように設計されています。
私たちのヘッジファンドは、市場/国/セクターおよびファクターに中立であるため、ターゲットは市場/国/セクターや一般的なファクターでは説明されない株式特有のリターンとして解釈できます。簡単に言えば、私たちが求めているのは「アルファ」です。
Signalsには、モデル性能の調整に役立つ3種類のターゲットがあります。
target_raw_return
公開データからリターンを自分で計算する場合、株式分割や配当などの要因で難しくなるため、正確なリターン列を構築するのが難しいことがあります。このターゲットはこれらの要因をすべて処理し、リターンをNumeraiの標準分布にビン分けします。このターゲットはICv2のスコアリングに使用されます。
target_factor_neutral 国、セクター、ベータ、モメンタム、サイズなどの標準ファクターに中立化されたターゲットです。このターゲットはRICおよびMMCの計算に使用されます。
target_factor_feat_neutral 多くのファクターおよびNumerai v4データセットのすべての特徴量に中立化されたターゲットです。これはSignalsデータセットの主要ターゲットで、CORRv4およびFNCv4のスコアリングに使用されます。
補助ターゲット 主要ターゲットに加えて、異なるタイプの株式特有リターンを示す多くの補助ターゲットも提供しています。これらも株式特有リターンに基づいていますが、残差化される要素や期間が異なります(例:市場/国vsセクター/ファクター、20日 vs 60日)。補助ターゲットで学習したモデルが主要ターゲットのモデルを上回ることもあります。
注意:補助ターゲットの一部にはNaN値が含まれる場合がありますが、主要ターゲットにはNaNが含まれません。
Signalsデータセットへの最適なアクセス方法はデータAPIです。
Numeraiデータセットは複数のファイルで構成されています。
データAPIを使用して、利用可能なファイルを確認し、ファイルをダウンロードする方法は以下の通りです。
train.parquet はティッカー、特徴量、およびターゲットを含む履歴データです。
validation.parquet はさらに多くの履歴データを含みます。
validation_example_preds.parquet は、例示モデルの検証予測を含みます。
import pandas as pd
from xgboost import XGBRegressor
# training data contains features and targets
training_data = pd.read_csv("numerai_training_data.csv").set_index("id")
# tournament data contains features only
tournament_data = pd.read_csv("numerai_tournament_data.csv").set_index("id")
feature_names = [f for f in training_data.columns if "feature" in f]
# train a model to make predictions on tournament data
model = XGBRegressor(max_depth=5, learning_rate=0.01, \
n_estimators=2000, colsample_bytree=0.1)
model.fit(training_data[feature_names], training_data["target"])
# submit predictions to numer.ai
predictions = model.predict(tournament_data[feature_names])
predictions.to_csv("predictions.csv")import numerapi
napi = numerapi.NumerAPI("public_id", "secret_key")
# download data
napi.download_current_dataset(unzip=True)
# upload predictions
napi.upload_predictions("predictions.csv", model_id="model_id")# setup your cloud infrastructure
numerai setup
# copy the example model
numerai docker copy-example
# deploy the example model
numerai docker deploy# method='first' breaks ties based on order in array
ranked_predictions = predictions.rank(pct=True, method="first")
correlation = np.corrcoef(labels, ranked_predictions)[0, 1]Cookieに安全なフラグの欠落
SSL の問題 (weak ciphers/key-size/BEAST/CRIME)
セキュリティへ影響を与えないCSRF
レート制限攻撃(重大なリスクを構成しない限り)
メールを送ることによるチェック
誤って構成されたDNSレコード(重大なリスクを構成しない限り)
小さなウェブサイトの表示問題、メールのエラー、壊れたリンク
0.1-1 NMR
ユーザーの資金を危険にさらすことのない軽微な問題や脆弱性
0.1-1 NMR
中程度のデータエラー、不正なペイアウト、予測ファイルの提出やNMRの預け入れができない
1-5 NMR
_大規模_な問題、セキュリティ問題、スマートコントラクトの脆弱性
1-100 NMR
小規模なウェブサイトの機能
1 NMR
中規模のデータ、予測ファイルの提出、NMR預け入れ方法の改善
1-5 NMR
大規模なTournamentのルール/ペイアウト、評価の改善
10-100 NMR
特定のラウンドのユーザーのMMCを計算するためには、以下の手順を実行します:
提出物の予測値とメタモデルの値を正規化する
提出物の予測値をメタモデルに対して中立化する
中立化された予測値とターゲットの共分散を計算する
Diagnosticでは、BMCはステーク加重のベンチマークモデルではなく、単一のモデルであるステークが最も高いベンチマークモデルに対して計算されます(こちらを参照)。LBとDiagnosticのBMCには違いがあります:
リーダーボード(LB)は Liveデータのパフォーマンスを表示します - これは、ここで計算されるBMCがNumeraiとデータサイエンティストがその時点で知っていたことに基づいているため、その時点でのステーク加重のベンチマークモデルに対してモデルを評価するのが公平です。初期のラウンドでは、ステーク加重のベンチマークモデルは単にv2データセットからの例の予測です。
Diagnosticは Validationデータのパフォーマンスを表示します - これは、より良いモデリング技術、より良いデータ、より良いターゲットを使用している可能性があり、v2データセットからの例の予測に対して評価するのは誤解を招く可能性があるためです。代わりに、できるだけ最新で最高のモデルに対して評価する必要があります。
BMCがLBとDiagnosticでなぜ異なるのかまだわからない場合は、ターゲットアンサンブルノートブックをご覧ください。
MMC & BMC についてもっと詳しく読みたい方はこちらをご参照ください。
feature_adv_20d_factor
feature_beta_factor
feature_book_to_price_factor
feature_country
feature_dividend_yield_factor
feature_earnings_yield_factor
feature_growth_factor
feature_impact_cost_factor
feature_market_cap_factor
feature_momentum_12w_factor
feature_momentum_26w_factor
feature_momentum_52w_factor
feature_momentum_52w_less_4w_factor
feature_ppo_60d_130d_country_ranknorm
feature_ppo_60d_90d_country_ranknorm
feature_price_factor
feature_rsi_130d_country_ranknorm
feature_rsi_60d_country_ranknorm
feature_rsi_90d_country_ranknorm
feature_trix_130d_country_ranknorm
feature_trix_60d_country_ranknorm
feature_value_factor
feature_volatility_factorfrom numerapi import NumerAPI
napi = NumerAPI()
[f for f in napi.list_datasets() if f.startswith("signals/v2.0")]
['signals/v2.0/train.parquet',
'signals/v2.0/validation.parquet',
'signals/v2.0/validation_example_preds.csv',
'signals/v2.0/validation_example_preds.parquet']
# トレーニングデータをダウンロード
napi.download_dataset("signals/v1.0/train.parquet")# https://github.com/numerai/numerai-tools/blob/master/numerai_tools/scoring.py
import numpy as np
import pandas as pd
from scipy import stats
def contribution(predictions: pd.DataFrame, meta_model: pd.Series, live_targets: pd.Series) -> pd.Series:
"""与えられた予測に関する与えられたメタモデルとの貢献相関を計算します。
その後、次の手順で貢献相関を計算します:
1. 各予測とメタモデルを順位付けし、順位を保持します
2. 各予測とメタモデルをガウス化します
3. 各予測をメタモデルに関して直交化します
4. 直交化された予測とターゲットを乗算します
引数:
predictions: pd.DataFrame - 評価する予測
meta_model: pd.Series - 評価対象のメタモデル
live_targets: pd.Series - 評価対象のライブターゲット
戻り値:
pd.Series - 予測の各列の結果の貢献相関スコア
"""
def rank(df: pd.DataFrame, method: str = "average") -> pd.DataFrame:
return df.apply(lambda series: (series.rank(method=method).values - 0.5) / series.count())
def tie_kept_rank(df: pd.DataFrame) -> pd.DataFrame:
# rank columns, but keep ties
return rank(df, "average")
def filter_sort_index(s1, s2, max_filtered_ratio=0.2):
ids = s1.dropna().index.intersection(s2.dropna().index)
# ensure we didn't filter too many ids
assert len(ids) / len(s1) >= (1 - max_filtered_ratio)
assert len(ids) / len(s2) >= (1 - max_filtered_ratio)
return s1.loc[ids].sort_index(), s2.loc[ids].sort_index()
def gaussian(df: pd.DataFrame) -> pd.DataFrame:
assert np.array_equal(df.index.sort_values(), df.index)
return df.apply(lambda series: stats.norm.ppf(series))
def orthogonalize(v, u):
return v - np.outer(u, (v.T @ u) / (u.T @ u))
# 予測、メタモデル、ターゲットをお互いにフィルタリングして並び替える
meta_model, predictions = filter_sort_index(meta_model, predictions)
live_targets, predictions = filter_sort_index(live_targets, predictions)
live_targets, meta_model = filter_sort_index(live_targets, meta_model)
# メタモデルと予測を順位付けして正規化して平均=0、標準偏差=1にします
p = gaussian(tie_kept_rank(predictions)).values
m = gaussian(tie_kept_rank(meta_model.to_frame()))[meta_model.name].values
# 予測をメタモデルに関して直交化します
neutral_preds = orthogonalize(p, m)
# ターゲットを中心化します
live_targets -= live_targets.mean()
# ターゲットと中立化された予測を乗算します
# 平均=0なので、これは共分散に相当します
mmc = (live_targets @ neutral_preds) / len(live_targets)
return pd.Series(mmc, index=predictions.columns)代替データシグナル(クレジットカード取引、衛星画像、ソーシャルメディアのセンチメント)
ブレンドシグナル(Barraリスクファクター、Fama Frenchファクター)
データ提供者の場合は、シグナルとして独自の特徴量を直接提出することができます。データサイエンティストの場合は、ユニークなデータをモデル化して予測をシグナルとして提出できます。シグナルは、我々のターゲットおよび他の提出されたシグナルと比較されてスコアリングされます。シグナルはNMR暗号通貨でステーキングすることができ、パフォーマンスに応じてNMRを獲得または失うことができます。
Numerai Data APIを使用して始めることができます:
高品質なシグナルを生成するには、独自の暗号市場データを取得する必要があります。MessariやCoinMarketCapなどのデータプロバイダを利用して始めることができます。
もし暗号市場データを持っていなくても、Numeraiに興味がある場合は、Numerai Tournamentで株式市場を予測してみてください。
データのモデリングをどこから始めるべきか分からない場合は、Numerai Tournamentで基本的なモデリング方法を学ぶことを強くお勧めします。モデリングスキルに自信がついたら、それをNumerai Cryptoに応用することができます。以下は、勾配ブースティングに基づくモデルの基本的な例です:
Numerai Cryptoの提出はNumerai Signalsと非常に似ています。ただし、株式ティッカーの代わりにトークンシンボルを使用します。提出は、各シンボルにリターンを予測する数値を持つリストであるべきです。
提出するシンボルのリストは、Numerai Cryptoのトークンユニバースで定義されています。数値は0から1の間であるべきです。
以下は、Pythonでライブ予測を生成し、アップロードする方法の例です:
スコアリングもまたNumerai Tournamentに非常に似ています。
Numerai Cryptoはトークンのリターンを予測するだけでなく、他のモデルが既に持っていない独自のシグナルを見つけることが目的です。
詳細はスコアリングセクションをご覧ください。
Numerai Tournamentと同様に、NMRを自分のモデルにステーキングすることで、パフォーマンスに基づいてNMRを獲得または失うことができます。詳細についてはステーキングのドキュメントをお読みください。
トークンユニバースとは何ですか?
取引可能な有名な暗号通貨トークンシンボルのセットです。Numeraiはこれらのシンボルのみの予測を求めています。詳細はこちらをご覧ください。
Numerai Tournament、Numerai Signals、およびNumerai Cryptoの違いは何ですか?
Numerai TournamentとNumerai Signalsは、ユーザーが株式市場を予測するためのトーナメントです。Numerai Cryptoは暗号通貨市場を予測するためのものです。Numerai CryptoはSignalsに最も似ており、ユーザーは独自の特徴量を使用する必要があります。Numeraiはモデルを訓練し、検証データで評価するための過去のターゲットファイルを提供しますが、ユーザーは独自の特徴量を収集し、処理してモデルを訓練する必要があります。
私のコード/データはNumeraiから保護されていますか?
はい。Numeraiはあなたのデータや予測を構築するコードを閲覧しません。Numeraiが受け取るのは予測そのものだけです。コードをリバースエンジニアリングすることはほぼ不可能であり、Numeraiもそのようなことに関心を持っていません。
参加するためにNMRをステーキングする必要がありますか?
いいえ。予測ファイルを提出して、ステーキングせずにパフォーマンスを受け取ることができます。
なぜ自分で取引しないのですか?
あなたが自分で取引することは可能ですし、私たちはそれを止めることはできません。しかし、Numeraiはあなたのシグナルが既に知られており、他の誰もが使用しているかどうかを教えてくれます。すべての人が既に取引しているシグナルを取引しても、それほど価値がありません。詳細はMediumの投稿をご覧ください。
参加するためにコーディングや金融の知識が必要ですか?
基本的なモデルや探索的ノートブックは提供されており、初めての方でも参加できますが、コーディングや金融に不慣れな方はNumerai Tournamentに参加することをお勧めします。Numerai Cryptoは、成功するために高いレベルのコーディングと市場知識が必要です。
Numeraiは暗号通貨を取引していますか?
いいえ。Numeraiは暗号通貨を取引しておらず、Numeraiのヘッジファンドも取引していません。
NumeraiはNumerai Crypto Meta Modelを使用していますか?
いいえ。Numeraiの他の製品、資産、またはサービスは、Numerai Crypto Meta Modelを使用、消費、ブレンド、または影響されていません。
Numerai Cryptoの予測やデータはNumeraiのヘッジファンドで使用されていますか?
いいえ。NumeraiのヘッジファンドはNumerai Cryptoと完全に分離されており、Numerai Cryptoから何もヘッジファンドに影響を与えません。
質問、サポート、フィードバックはDiscordでご連絡ください!
from numerapi import NumerAPI
import pandas as pd
napi = NumerAPI()
napi.download_dataset("crypto/v1.0/train_targets.parquet")
training_data = pd.read_parquet("crypto/v1.0/train_targets.parquet")import lightgbm as lgb
import pandas as pd
import random
from numerapi import NumerAPI
from typing import List
napi = NumerAPI()
def generate_training_features(df: pd.DataFrame) -> List[str]:
# TODO: データを取得して特徴量を作成
df['fake_feature_1'] = df.groupby(["symbol", "date"])['symbol'].transform(lambda x: random.uniform(0, 1))
return ['fake_feature_1']
# 過去のターゲットファイルには["symbol", "date", "target"]の列が含まれています
napi.download_dataset("crypto/v1.0/train_targets.parquet")
train_df = pd.read_parquet("crypto/v1.0/train_targets.parquet")
# 各(symbol, date)に対してトレーニング特徴量を追加
feature_cols = generate_training_features(train_df)
model = lgb.LGBMRegressor(
n_estimators=2000,
learning_rate=0.01,
max_depth=5,
num_leaves=2 ** 5,
colsample_bytree=0.1
)
model.fit(
train_df[feature_cols],
train_df["target"]
)def generate_features(df: pd.DataFrame):
# TODO: ライブユニバース用にデータを取得し特徴量を作成
df['fake_feature_1'] = df['symbol'].transform(lambda x: random.uniform(0, 1))
# APIキーを使用して認証
napi = NumerAPI("[your api public id]", "[your api secret key]")
# 最新のライブユニバースをダウンロード
napi.download_dataset("crypto/v1.0/live_universe.parquet")
live = pd.read_parquet("crypto/v1.0/live_universe.parquet")
# ライブユニバースの特徴量を生成
generate_features(live)
# ライブ予測を取得
live["signal"] = model.predict(live[feature_cols])
# 予測は0から1の間である必要があります
live["signal"] = live["signal"].rank(pct=True)
# 提出をフォーマットし保存
live[['symbol', 'signal']].to_parquet("submission.parquet")
# モデルIDを取得し、モデルを提出
models = napi.get_models(tournament=12)
for model_name, model_id in models.items():
print(f'submitting {model_name}...')
napi.upload_predictions("submission.parquet", model_id=model_id, tournament=12)
print('done!')検証およびライブの予測はNumerai APIを介して利用できます。
すべての予測はウォークフォワードフレームワークを使用して行われます。これは、すべての予測が、予測が行われる日付より前に利用可能なデータのみを使用してトレーニングされたモデルを使用して行われることを意味します。
具体的には、データは156Eraのチャンクに分割されます。それから、各Eraチャンクごとに、最初のEraチャンクからパージEraまでトレーニングされたモデルによって予測が行われます。パージEraの数は、20Dターゲットの場合は8であり、60Dターゲットの場合は16です。
したがって、モデルはEra1〜148でトレーニング、Era149〜156がパージ、Era157〜312で評価します。 次のモデルはEra1〜304でトレーニング、Era305〜312がパージ、Era313〜468で評価します。 ウォークフォワード交差検証のウィンドウは以下のようになります。
1
1
148
157
312
2
1
304
313
468
すべてのモデルは、以下のLGBMパラメータを使用します:
より多くの木を持つことが役立つことがわかりましたし、より深い木を持つことでより少ない木でも同様の結果が得られることもわかりました。詳細はこちらをご覧ください:https://forum.numer.ai/t/super-massive-lgbm-grid-search/6463
すべてのアンサンブルは、以下の手順を使用します:
各Eraごとに予測をガウス化する
標準偏差が1になるように標準化する
予測を、各モデルごとに望ましい重みを表す重みベクトルとドット積する
結果の予測ベクトルをガウス化し、中和する特徴がある場合は中和する
ステップ1、2、および3は次のようになります:
一部のモデルには中和(neutralize)が含まれています。これは、各特徴への予測の露出度を求めるために回帰を行い、その露出度を予測ベクトルから差し引いて、その結果がすべてのその特徴に直交するベクトルになるようにすることです。
以下は、いくつかの予測列(columns)をいくつかの特徴(ニュートラライザー)で中和するコードです。
{data_version}_LGBM_{target}
これらは、データバージョン(V2、V3、V4、V41、V42、V43、V5)とターゲットの組み合わせを持つ多くのモデルがあります。
これらは、標準のウォークフォワード方法でトレーニングされたモデルであり、標準的なLGBMパラメータを使用し、指定されたデータバージョンとターゲットを使用しています。それだけです!
https://numer.ai/~benchmark_modelsから最新のデータバージョンのモデルを確認することができます。


現在、支払いに使用されている主なスコアは2つあります。
特徴ニュートラル相関 (FNCv4):中和された予測とターゲットとの相関
このために使用されるターゲットは target_factor_feat_neutral_20(一般的な特徴と因子に対して中和されたリターン、「残差リターン」を生成)です。
メタモデル貢献度(MMC)に置き換えられます。
また、支払いには使用されない情報提供用のスコアもあります。
(CORRv4):予測とターゲットとの相関
情報係数 (ICv2):予測と未調整リターンとの相関
残差情報係数 (RIC):予測と残差リターン(一般的な因子に中和されたリターン)との相関
詳細な説明については、をご覧ください。
信号やターゲットは、既存の信号と相関がゼロであるとき「ニュートラル」と見なされます。中和の目的は、既存の信号に含まれていないオリジナルまたは直交成分を抽出することです。
よく知られた信号の単純な線形結合を提出すると、中和後には直交成分がほとんど残らない場合があります。
Numeraiには、サイズ、価値、モメンタムなどのBarra因子、国やセクターのリスク因子、カスタム株式特徴など、さまざまな既存の信号があります。これらの既存の信号は提供されないため、このプロセスは「ブラックボックス」となります。信号を中和するためのコードはオープンソースであり、このプロセスについてはで学ぶことができます。
スコアリングの前に信号を中和することで、Numeraiはターゲットを中和し、データを提供せずにそのパフォーマンスを向上させる可能性があります。たとえば、信号が国のリスクに対して中和されていない場合、Numerai Signalsはスコアリング前にその信号を国のリスクに対して中和します。これにより、国のリスクの中和を気にせずオリジナルな信号を作成することに専念できます。
信号が単独では強力な予測力を持っていても、Numerai Signalsでのスコアが低くなることがあり、Signalsのユニークな特徴を際立たせています:Numerai Signalsは株価リターンの予測ではなく、Numeraiがまだ持っていないオリジナルな信号を見つけることです。
特徴のエクスポージャーや中和の広範な影響について理解を深めるには、をご覧ください。
Signalsは、Numeraiが作成したカスタムブラックボックスのターゲットに対して評価されます。このターゲットもNumeraiトーナメントと同様に20D2L(20日後、2日のラグ)のターゲットですが、既存の信号に対して中和されています。
短い期間のターゲットは使用しません。短期的な期間でのみ機能する信号は、大規模なヘッジファンドにとって実用化が難しいからです。たとえば、1時間の株価リターンを正確に予測できる信号があっても、ヘッジファンドがそのポジションを完全に取引するのに24時間かかる場合、それはあまり役に立ちません。大規模なヘッジファンドにとって有用な信号は、長期的に予測力を持ち、「低アルファ減衰」としても知られます。
信号の履歴診断を使用して、パフォーマンスを確認し、将来の信号に対する中和の影響を見積もることができます。重要なのは、履歴期間でスコアが強い信号でも、現在や将来のラウンドで高いスコアを得られるとは限らないことです。
診断ツールは、ページのモデル横にあるビーカーのアイコンから開くことができます。過去のvalidation期間にわたる信号をアップロードすると、パフォーマンス、リスク、潜在的な収益などのvalidationメトリクスが計算されます。validation期間は 20130104 からvalidationデータの最新日までです。
validation期間にわたるアップロードには、次の追加列が必要です:
date列 - 履歴データは週単位で、診断ツールは特定の週の予測がその週の最新の金曜日の市場終値データを使用していると仮定します。
アップロードが確認されると、診断が開始されます。通常、これには5~10分かかりますが、提出する週数やティッカーの数に依存します。
これらの診断は、信号がステーキングする価値があるかどうかを判断するための指標です。validation期間での診断が良好であっても、現在または将来のlive期間で高いスコアを得られるとは限らないことに注意が必要です。
この履歴評価ツールを繰り返し使用すると、すぐに過学習を引き起こします。診断は信号作成プロセスの最終確認としてのみ使用してください。
チャーンとは、信号が時間とともにどれだけ変化するかを示す統計です。Signalsで使用しているチャーンを計算するコードはオープンソースで公開されており、で確認できます。
簡潔に示すと以下の通りです。
churn(t0, t1) = 1 - correlation(s(t0), s(t1))
ここで、s(t) は時点 t における信号の提出物を表します。
Signalsの提出物に高いチャーンがある場合、Numeraiはその信号を取引できません。もともとNumeraiトーナメントデータを基にした多くのモデルは、自然に低いチャーンを持っていますが、Signalsモデルは高いチャーンを持つ傾向があります。
Signalsメタモデルのチャーンは、個別のSignalsモデルの平均チャーンと強い相関があるため、Numeraiは高チャーンのSignalsモデルを許可できません。
前週に提出していないモデルはステークが0に設定されます。これは、毎週提出していないモデルは自動的にメタモデルの高いチャーンを引き起こすためです。
モデルが先週以内に提出している場合、新しい提出物のアップロード時に、前週の提出物との最大チャーンを計算します。現在のアップロード期間を時点 t とした場合、最大チャーンは次のように定義されます:
max_churn = max([churn(t, t-1), churn(t, t-2), ..., churn(t, t-5)])
もし max_churn が15%以上であれば、その提出物のステークは0に設定されます。
D: 土日を除いた日数。20Dならば土日を除いた20日(土日を含めて28日)を表す。
L: ラグ。2Lならば2日ラグがあることを表す。
ビン数: targetの値が何個ビン化されているか。5なら5つの数字にビン化されていることを表す。
均一性: ビン化されている数字の分布。均一性が10%、40%、50%は0と1が5%ずつ、0.25と0.75が20%ずつ、0.5が50%を表す。
target_20d
タイムライン:20D2L
ビン数=5、均一性=10%、40%、50%
ニュートラライザー:標準因子およびその他の未リスト化の因子
Signalsの提出物は以下の手順でクリーンアップされます:
各提出物をtie-keptランクにする
各提出物のnanを0.5で埋める
各提出物をtie-keptランクにする
スコアリングで使用する前に提出物がクリーンアップされます:
無効なティッカーを削除
提出物をtie-keptランクにする
nanを0.5で埋める
モデルアップロードは、毎日の投稿を自動化するシンプルで無料の方法です。
Liveデータを受け取り、ライブの予測を出力する関数でモデルをラップします。
で関数をpickle化し、pickleされたファイルをNumeraiにアップロードします。
Numeraiがあなたのモデルを毎日実行し、でLiveデータの予測を行います。
以下に簡単な例を示します。以下のように、liveのデータをpandasで受け取り、pandasのdataframeでデータを返すような関数をcloudpickleでpickle化することで完了します。
なども参照してください。
の右側にあるUpload Modelボタンを見つけてください。
モデルのアップロードボタンをクリックし、アップロードモーダルを開きます。アップロードしたいpickleファイルを選択し、pickleの作成に使用したPythonのバージョンを設定し、Uploadをクリックします。
アップロードが完了すると、Numeraiは直ちにあなたのモデルを実行し、現在のラウンドのライブサブミッションを生成し、検証データセットに対して診断を生成します。
これらが完了すると、投稿欄に投稿ブロックが表示され、最新の投稿欄に成功ステータスが表示され、診断欄に診断結果を表示するリンクが表示されます。
上記のアップロードが完了すると、以下の4つのステータスで最新の投稿サイクルを見ることができます:
Pending: Numeraiは、あなたのモデルを実行するためにクラウドリソースをプロビジョニングしています。
Running: Numeraiはあなたのモデルを実行中です。
Validating: Numeraiはあなたのモデルを実行し、現在あなたの提出を検証しています。
Success: Numeraiはあなたの投稿を受理しました。
問題があった場合、2つのステータスが表示されます:
Error: Numerai はあなたのモデルを実行する際に予期せぬエラーに遭遇しました。
Failed: モデルの実行に失敗しました。ログを確認し、動作するモデルを再アップロードしてください。
モデル失敗の例としては、以下が考えられます。
Pythonまたは依存関係のバージョンの不一致
投稿が無効(フォーマットエラーなど)
メモリ不足
タイムアウト
エラーが出る場合、以下の「Numerai predictを理解する」も参考にしてください。
Cloudpickleは、ローカルのPythonコードをクラウド上で簡単にリモート実行できるライブラリです。.NETや.NETのような人気のある分散コンピューティングフレームワークの裏で使われています。
cloudpickleを使う主な利点は、コードと一緒にローカルコンテキストをシリアライズしてくれることです。そのため、Google Colabのようなノートブック環境でローカルに開発したコードをパッケージ化するのにとても便利です。
下の例では、関数はグローバルスコープで定義されたmodelとfeature_colsを参照しています。Cloudpickleは賢いので、modelとfeature_colsの両方を値によって正しくシリアライズし、この関数がNumeraiによって実行されるときにも利用できるようにします。
はモデルの実行環境です。
cloudpickleはローカル環境のPython自身やPythonライブラリをシリアライズしないので、あなたのコードがNumerai PredictでサポートされているPythonのバージョンやライブラリと互換性があることを確認する必要があります。
問題をデバッグする際には、numerai-predict dockerコンテナをダウンロードしてローカルでテストすることが役に立つかもしれません。
ローカルで以下のコマンドを叩くことでエラーの詳細を知ることができます(参考:)。
私たちは、すべての業界標準のPython機械学習ライブラリをサポートすることを目指しています。あなたのパイプラインが現在サポートされていないライブラリを使用している場合は、お知らせください。
セキュリティ上の理由から、アップロードされたモデルはインターネットにアクセスできません。
また、各モデルに1CPU、4GBのRAMを搭載したマシンを用意し、最大10分のランタイムを許可します(キューに入る時間は含みません)。
参考までに、いくつかの例のランタイムを示します。
small特長量(32個)、2万個(20k)の木を使ったLGBMモデルは、small特長量を使って1分未満
全特長量(>1000特長量)、9万個(90k)の木を使ったLGBMモデルの実行時間は6分未満
model uploadを行うと、Numerai compute経由での送信が無効化されます。
この機能は、インフラの設定や管理に時間を費やしたくない、新規〜中級ユーザー向けに設計されています。
この機能のデメリットとしては、学習済みモデルをアップロードする(そしてNumeraiにアクセス権を与える)必要があることです。
この点に抵抗がある場合は、などを検討してください。
Numeraiは、セキュリティ上の懸念やアカウントがアクティブでなくなった場合など、いかなる理由でもあなたのモデルを無効にする権利を留保します。
Numeraiは、この機能の使用をサポートするために最善を尽くしますが、最終的には、あなたの投稿パイプラインが適切に設定されていることを確認するのはあなたの責任です。
!pip install numerapi
from numerapi import NumerAPI
napi = NumerAPI()
napi.download_dataset("v5.0/train_benchmark_models.parquet", "train_benchmark_models.parquet")
napi.download_dataset("v5.0/validation_benchmark_models.parquet", "validation_benchmark_models.parquet")
napi.download_dataset("v5.0/live_benchmark_models.parquet", "live_benchmark_models.parquet")standard_large_lgbm_params = {
"n_estimators": 20000,
"learning_rate": 0.001,
"max_depth": 6,
"num_leaves": 2**6,
"colsample_bytree": 0.1,
}# https://forum.numer.ai/t/benchmark-models/6754/9を元に少し改変
def rank_gauss_pow1(s: pd.Series) -> pd.Series:
# 順位を正規化
s_rank = (s.rank(method="average") - 0.5) / s.count()
# ガウス化
s_rank_norm = pd.Series(stats.norm.ppf(s_rank), index=s_rank.index)
# 標準偏差1に標準化
result_series = s_rank_norm / s_rank_norm.std()
return result_series
ensemble_cols = ["V4_LGBM_NOMI20", "V42_RAIN_ENSEMBLE"]
weight_vector = [0.1, 0.9]
for col in X[ensemble_cols]:
if "era" in X.columns:
X[col] = X.groupby("era", group_keys=False)[col].transform(lambda s1: rank_gauss_pow1(s1))
else:
# Xが単一のEraのみを含むことを確認します
assert 1800 < X.shape[0] < 6000
X[col] = rank_gauss_pow1(X[col])
return X[ensemble_cols].dot(weight_vector)def neutralize(df, columns, neutralizers=None, proportion=1.0, era_col="era"):
if neutralizers is None:
neutralizers = []
unique_eras = df[era_col].unique()
computed = []
for u in unique_eras:
df_era = df[df[era_col] == u]
scores = df_era[columns].values
scores2 = []
for x in scores.T:
x = pd.Series(x)
x = (x.rank(method="first") - 0.5) / len(x.dropna())
x = stats.norm.ppf(x)
scores2.append(x)
scores = np.array(scores2).T
exposures = (
df_era[neutralizers]
.fillna(df_era[neutralizers].median())
.fillna(0.5)
.values
)
scores -= proportion * exposures.dot(
np.linalg.pinv(exposures.astype(np.float32), rcond=1e-6).dot(
scores.astype(np.float32)
)
)
scores /= pd.DataFrame(scores).std(ddof=0, axis=0, skipna=True).values
computed.append(scores)
return pd.DataFrame(np.concatenate(computed), columns=columns, index=df.index)3
1
460
469
624
4
1
616
625
780
...
...
...
...
...
target_20d_factor_neutral
タイムライン:20D2L
ビン数=5、均一性=10%、40%、50%
ニュートラライザー:標準因子およびその他の未リスト化の因子
target_20d_factor_feat_neutral
タイムライン:20D2L
ビン数=5、均一性=10%、40%、50%
ニュートラライザー:標準因子およびその他の未リスト化の特徴
各提出物を正規化する(ガウス化)
Signals ステーク加重メタモデル(最小ステークあり)(SSWMM)
クリーンアップされたSignals提出物のステーク加重平均
Signals ナイーブ加重メタモデル(最小ステークあり)(SNWMM)
クリーンアップされたSignals提出物の平均
Signals ナイーブ加重メタモデル(最低10 NMRのステークあり)(SNWMMmin10)
最低10 NMRのステークを持つクリーンアップされたSignals提出物の平均
MMC - メタモデルへの貢献度
提出物、SNWMMmin10、target_20d_factor_neutralとの相関による貢献度
タイムライン:20D2L(データ遅延2日)
CORRV4 - 相関v4
提出物とtarget_20d_factor_feat_neutralの相関
スコア日数20日、リターン遅延2日(+ データ遅延2日)
ICV2 - 情報係数V2
ビン化されたリターンと提出物のスピアマン相関
スコア日数20日、リターン遅延2日(+ データ遅延2日)
RIC - 残差情報係数
target_20d_factor_neutralと提出物のスピアマン相関
スコア日数20日、リターン遅延2日(+ データ遅延2日)
FNCV4 - 特徴ニュートラル相関v4
提出物をtie-keptランク化、正規化、ニュートライズする
target_20d_factor_feat_neutralと提出物のtie-brokenランク相関
ニュートラライザー:標準因子とV4中間セーフ特徴
スコア日数20日、リターン遅延2日(+ データ遅延2日)
CWSNMM - Signalsナイーブメタモデルとの相関
s' = 提出物sをtie-keptランク化、正規化、1.5乗
s'とSNWMMのピアソン相関を計算
タイムライン:データ遅延4日 / リターンに依存しない
MCWSM - Signalsモデルとの最大相関
提出物の他のSignals提出物との最大ピアソン相関
同ラウンドで行われた他の提出物と比較
タイムライン:データ遅延4日 / リターンに依存しない
APCWSM - Signalsモデルとの平均ペア相関
提出物と他のSignals提出物の平均ピアソン相関
同ラウンドで行われた他の提出物と比較
タイムライン:データ遅延4日 / リターンに依存しない








# Wrap your model with a function that takes live features and returns live predictions
def predict(live_features: pd.DataFrame) -> pd.DataFrame:
live_predictions = model.predict(live_features[feature_cols])
submission = pd.Series(live_predictions, index=live_features.index)
return submission.to_frame("prediction")
import cloudpickle
p = cloudpickle.dumps(predict)
with open("predict.pkl", "wb") as f:
f.write(p)def predict(features: pd.DataFrame) -> pd.DataFrame:
# modelとfeature_colsはグローバルスコープで定義されます。
live_predictions = model.predict(features[feature_cols])
submission = pd.Series(live_predictions, index=features.index)
return submission.to_frame("prediction")docker run -i --rm -v "$PWD:$PWD" ghcr.io/numerai/numerai_predict_py_3_10:stable --model $PWD/model.pkl
Crypto Signalsの作成に使用される基礎データは非常に異なる場合があります(監査済みの財務データ、ニュース記事、駐車場の画像など)が、Crypto Signals自体はすべて基本的なフォーマットで提供されます。これは、トークンシンボルのリストとそれぞれに関連付けられた数値の組み合わせです。
あなたの提出で使用するトークンシンボルのリストは、Numerai Cryptoのトークンユニバースによって定義されています。このリストは、世界で最も大きなトークン上位300位程度をカバーしており、毎日更新されます。一般的に、1日に移動するのは少数の低ボリュームのトークンですが、これは市場のボラティリティに依存し、暗号通貨は非常に不安定であることは誰もが知っている通りです。
最新のユニバースは、live.parquetファイルをダウンロードすることで確認できます。
トークンユニバースは、時価総額で上位300のトークンで定義されており、以下のものを除きます:
ステーブルコイン、ラップトークン、リキッドステーキングトークン(例:stETH, rpETH)
2年未満のトークン
過去24時間で100万ドル未満の取引量のトークン
重複するシンボルのうち時価総額が低いトークン
上記が除外された後、以下の条件でさらにトークンが除外されます:
安定しすぎている:6ヶ月間の平均日次リターンが0.00001未満のトークン
高い相関:過去6ヶ月間のデイリーリターンの相関が0.95以上のトークンを除外し、最も時価総額が高いものを残します。
シグナルを提出する際には、少なくとも2つのカラムを含める必要があります:
symbol カラム - 値はライブユニバース内の有効なシンボルでなければなりません。
signal カラム - 値は0と1の間かつ排他的でなければなりません。
さらに、ライブ提出が有効であるためには:
ユニバースから少なくとも100のシンボルが有効な値(0から1)を持っていなければなりません。
シンボルは1回だけ表示される必要があります。
APIを使用して提出のワークフローを自動化することができます。提出APIは、ParquetとCSVファイル形式の両方をサポートしています。以下は、NumerAPIを使用して提出をアップロードする例です:
次のいずれかを使用することができます:
Numerapi(公式Pythonクライアント)
他の言語向けのRaw GraphQL API
オープンソースのクラウド自動化ツールであるNumerai Compute

from numerapi import NumerAPI
# 認証
napi = NumerAPI("[your api public id]", "[your api secret key]")
napi.upload_predictions("[path to your submission]", tournament=12)








この記事は、tit_BTCQASHのqiita記事に従います。元記事そのままなので、そっちを読んだ方が良いかもしれません。
Numerai-CLIは予測ファイルの提出を自動化できるフレームワークです。Numerai CLI 0.1または0.2を使用している場合は、以下のアップグレードガイドに必ず従ってください。
numerai-cli は毎週の予測ファイル提出を自動化するのに役立つコマンドラインツールです。本ツールを使用することで、提出期限に遅れることなく予測ファイルを自動で提出できます。
にウェブフックのURLを追加すると、Numeraiは土曜日の19:00 UTC(日本時間で04:00)(ラウンド開始から1時間後)に自動で実行されます。 Numerai-cliを使用せず、独自環境で予測ファイルの自動投稿をしたい場合、本部分を修正してください! もし、日曜日の2:00 UTC(日本時間で11:00)までに予測ファイルが提出されなかった場合は、警告メールをお送りします。 二回目の実行も失敗した場合は、日曜日の19:00 UTC(日本時間で04:00)に再度実行されます。それでも失敗した場合は、月曜日の2:00 UTC(日本時間で11:00)にメールでお知らせします。
今回の記事では、Numeraiに自動で予測ファイルを提出するを紹介します。Numerai CLIとは、Numeraiの予測ファイルを自動で提出できるように支援するパッケージです。
古いwindows(win8など)を使用している方は、本記事の手順通りにインストール・アクチべートすることをお勧めします。windows10,Linuxユーザーの方はすんなりとインストールできるらしいので、win8にかかわる部分は読み飛ばしてください。
AWS(amazon web service)の設定
Numerai APIキーの取得
Python・Dockerの設定
numerai-cliの使い方 5.numerai computeを使用するまでの手順
windows8.1 Pro, Intel Core i5 9600K メモリ 32GB
AWSはAmazonが運営しているクラウドコンピューティングサービスの一つです。Amazonが持っているCPU/GPUなどをオンラインで使用できるのでタスクの自動化に向いています。Numerai Computeノードをセットアップし、モデルをデプロイするまでを説明します。
1.AWSのアカウントを作成する。 AWSのアカウントの作成方法はを参照ください。連絡先情報・クレカの番号が必要となりますが、新規登録者は無料枠の分までは無料です。
2.AWSの請求を有効にする。 にし、コードを実行できるようにします。公式曰く、月当たり5USD以下の費用がかかるそうです。
3.IAM ユーザーの事前設定。 (Identity and Access Management)とはAWS のアクセスを安全に管理するためのウェブサービスのことです。 アカウント作成時点では、ルート権限を持つユーザーが作成されますが、IAMユーザーの設定をすると、特定の権限を持ったユーザーを作成することができます。今回は、Numeraiに自動で予測を提出するためだけのユーザーを作成します。 まず、を開いた後、JSONをクリックしてください。初期時点ではコードが入っていますが削除し、以下のコードをペーストしてください。
(*古いNumerai-cliを使用している方は、本部分が以下のコードと違う可能性があります。その場合は、以前のコードを削除し、以下のコードと置換してください。以前のコードのままだと、IAMの権限エラーが出て詰みます。)
次のステップボタン(右下)を二回クリックすると、以下の画面になります。
本画面の名前の部分に、任意の名前(例えばcompute-setup-policy)を入れてください。こちらの名前を後で使います。
4.IAM ユーザーの作成 IAMユーザーの作成を行うために、から設定を行います。ユーザー名に先ほど設定した名前(例えばcompute-setup-policy)を入れ、プログラムによるアクセスにチェックを入れた後、次のステップを押してください。
既存のポリシーを直接アタッチを押し、先ほど作成した名前で検索してください。その後、チェックボックスにチェックをいれ、次のステップを二回押してください。
入力した後、ユーザーの作成を押せばIAMユーザーの設定は完了です。アクセスキー IDとシークレットアクセスキーが表示されるので、メモしてください。
Numerai APIキーはから取得することができます。Create API Keyから Upload submissionsにチェックを入れた状態でAPIキーを作成してください。
Windowsユーザー向けの設定方法を説明します。 numerai-cliを動かすには、python,dockerが必要です。自動でインストールするスクリプトが用意されているので、windows10を利用されている方は以下のコードを入力してください。
このコードがうまく動いた人は以下の手順は不要です。
windows8環境場合は、以下の手順でPython,Docker-toolboxを導入します。 特にDockerのインストールは多種多様なエラーが出ます。うまくいった例を説明しますが、環境によっては再現しないこともあることをご了承ください。
①Pythonのインストール からPython 3.9.2をインストールしてください。インストール後はPathを通してください。(個人によって異なりますが、例えば、C:\Users\USER\AppData\Local\Programs\Python\Python39\Scripts\ をPathに追加してください)
②Docker-toolboxのインストール Dockerのインストールは『非常に』エラーが起きやすいです。以下の手順でインストールしてください。
i)visualboxのインストール から最新版のVisualboxをダウンロードし、インストールしてください。 ii)Docker-toolboxのインストール からDockerToolbox-18.02.0-ceをダウンロードし、インストールしてください。インストールするときに、Visualboxのチェックを**『絶対に』**外してください。() Gitのインストールは同時に行っても問題ありませんので、Gitにチェックを入れてください。
(このインストール方法に気が付くまで2日かかりました。Docker-toolboxからvisualboxをインストールすると、Numerai cliを使用できないので、必ずこの手順を守ってください)
iii)docker-machineの設定 docker quickstart terminalを起動し、以下のコードを入れてください。
以下の画像のように表示されればDockerの設定は問題ありません。
次に、Numerai computeで使用するdockerイメージの作成を行います。以下のコードを入力してください。
*Dockerが見つからない、などのエラーが出た場合は、パスが通っていないので、コントロールパネルからシステムの詳細設定を開き、環境変数→新規を押し、Pathを下図のように設定してください。 (docker toolboxの保存場所は環境によって異なる可能性があります。今回の場合はC:\Program Files\Docker Toolboxでした。)
** Docker daemon not running. Make sure you've started "Docker Quickstart Te rminal" and then run this command again. というエラーが出た場合は、次のコードでdefault を再起動してください。
それでもエラーが出る場合は、
を入力して出てくる、
を入力してください(環境によってこの部分は異なる可能性があります。)
これでdefaultのアクティブ化ができたはずです。(ACTIVEが*になればOK)
iv) pipとnumerai-cliのインストール を参考にpipをインストールしてください。 pipを入れたら、
として、numerai-cliをインストールしてください。
Docker quick start terminal上で"numerai --help"と打つと、使用できるコマンドリストが取得できます。
numerai copy-example: Numerai運営が用意したexampleファイルをダウンロードできます。
などとすることで、Numerai Tournament用のexampleファイルや、Signals用のファイルをダウンロードできます。
numerai doctor: numerai-cliの状態を取得します。正常なら、以下のようになります。
numerai list-constants: デフォルトの状態を表示します。
numerai node: DockerFileをAWSにアップロードするためのコマンドです。config, deploy, testをよく使います。
numerai setup: Numerai cliとAPIキーを初期化するコマンドです。記事上部で用意したNumerai public IDやAWSのキーを保存できます。
numerai uninstall: Numerai cliに関連するファイル・AWSの設定などをすべてアンインストールします。
numerai upgrade: .numeraiフォルダにkeyファイルなどを格納します。
i)numerai setupを実行し、Numerai public IDやAWSのキーを保存する。
ii)numerai upgradeを実行し、.numeraiフォルダに必要な情報を移す
iii)numerai copy-example -e tournament-python3 を実行し、tournament-python3フォルダを作成する
iv)cd tournament-python3 として、tournament-python3フォルダに移動する。
v)prediction.pyを開き、MODEL_CONFIGS内のNoneを自分のモデルのUUIDに変更する。
(UUIDの取得は)
vi)numerai node -m tit_btcqash_compute config -e tournament-python3 -s mem-md (tit_btcqash_computeの部分は個人によって異なります。モデル名を入れてください)を実行する。
(本コードは、tournament-python3フォルダのdockerfileを使用して、mem-mdで構成されたCPU/メモリーをAWSで構成する、というものです)
vii)numerai node deploy を実行し、AWSに必要情報をアップロードする
viii)numerai node testを実行し、正常に動作するか確かめる。
i)~viii)が実行できればnumerai-computeを使用する準備はできました。 predict.pyを書き変えて自分のモデルをアップロードしてみましょう。pklファイルなどもpredict.pyと同じフォルダにおいておけば、自動でAWSにアップロードしてくれます。 なお、新しいモデルをアップロードするときは、
を実行してからi)~viii)の手順を実行するとうまくいくと思います。
本記事が参考になった方はNMRを投げてくれるとtit_BTCQASH氏がきっと喜びます。 NMR:0x0000000000000000000000000000000000021d96
ステップバイステップのに従うか、のビデオをご覧ください。
で助けを求めてください。
pip3 install numerai-cli
mkdir example-numerai
cd example-numerai
# set up your compute node in AWS
numerai setup
# copy a python example model
numerai docker copy-example
# build the docker container and deploys it to AWS
numerai docker deploy
# trigger your compute node in AWS
numerai compute test-webhook
# watch the logs of the running compute node from AWS
numerai compute logs -f対象となっている株式市場に対応したSignalsをアップロードすると、過去のパフォーマンス、リスク、収益性の診断ができます。
現行のコンペティションにNMRをステーキングすると、性能(Corr,MMC)に基づいてNMRを得られます。ただし、品質の低いSignalsではNMRを失うこともあります。
NumeraiのAPIに直接接続することで、毎週のSignals提出を自動化することができます。
株式市場のSignalsとは、Numeraiのようなクオンツ・ファンドがポートフォリオを構築するために使用するデータのことです。
株式市場のSignalsの例としては、次のようなものがあります。
テクニカルSignals (MACD, RSI, MFI)
(, )
これらのSignalsを生成するために使用される基礎データは、異なったフォーマットをもつ可能性が高いです。 例えば、監査済みの財務報告書と駐車場の画像は全く異なるデータですが、明日の株式市場を予測する指標が含まれているかもしれません。 Numeraiが参加者のデータを利用するためには、規格化が必要です。参加者はティッカーとSignalsデータが一対一で対応するようなリストを作成する必要があります。
独自のSignalsを作成するためには、まず、いくつかの株式市場のデータを取得する必要があります。
まだ株式市場のデータにアクセスできていない場合は、 Yahoo Finance、Quandl、 Koyfin など、インターネット上に無料または格安のデータプロバイダーが多数存在します。
また、 Quantopian、QuantConnect、Alpaca などのSignalsを簡単に作成できるプラットフォームもあります。特に、Risk Model とAlphaLens Tearsheets は、Signalsの品質を分析するのに最適な方法です。 私たちのコミュニティで使用されている人気のあるデータソース、プラットフォーム、ツールのリストについては、このforum thread をチェックしてください。
ユニークで差別化されたデータセットを見つけることが、オリジナルのSignalsを生み出す鍵となります。
ユニバースは世界の上位5000の大型株を含んでいます。
ユニバースは毎週更新されますが、更新対象となるのは出来高の少ない数銘柄のみです。
Numerai dataから最新のユニバースを見ることができます。
作成したデータをNumerai Signals に提出する際は、少なくとも2つの列を含める必要があります。
cusip、sedol、またはbloomberg_ticker 列 - 値はヘッダーのticker タイプに関連付けられた有効なティッカーでなければなりません。
signal 列- 値は0から1の間でなければなりません(排他的)。
さらに、有効な提出をするためには:
現在の期間の予測を含む行が少なくとも10行ある必要があります。
同じティッカーを複数回使用することはできません。
2列のみの予測結果は、現在のlive時間帯に対応していると仮定します。
また、Signalsを提出すると過去のパフォーマンス、リスク、潜在的な収益に関する診断もできます。検証期間は20130104から20200228までの374週間です。
検証期間を含む予測結果には、friday_date,data_type列を含める必要があります。
friday_date 列 - Numerai Signals では、コンペティションの開始が金曜日なので、金曜日に相当する日付をいれる必要があります。
data_type 列 - 値はliveまたはvalidationのみを取り得ます。data_typeがliveの行には、直近の金曜日の日付が含まれていなければなりません。
最新の提出例はこちらからダウンロードできます。
Signalsを提出すると、過去のパフォーマンス、リスク、潜在的な収益の診断ができます。これは通常、提出物に含まれている週数やティッカー数に応じて10~15分程度かかります。
これらの診断を用いると、NMRをステークする価値があるかを評価できます。ただし、過去の検証期間中に高いパフォーマンスが出たSignalsは、現在または将来のライブ期間で良いスコアが得られない可能性があることに注意すべきです。
この診断ツールを繰り返し使用すると、すぐにオーバーフィッティングにつながります。診断は、Signals作成プロセスの最終チェックとしてのみ使用してください。
Numerai-CLI、GraphQL API 、公式 python クライアントを使用することで、投稿ワークフローを自動化することができます。
Numeraiは様々な既存のデータをもっています。既存のSignalsには、Barra ファクター(サイズ、バリュー、モメンタムなどのようなもの)、国やセクターのリスクファクター、custom stock features などが含まれています。
Numerai Signalsにアップロードされた全てのSignalsは、スコアリングされる前に中和されます。中和のポイントは、既知のSignalsに存在しないSignalsの独自成分あるいは直交成分を分離することです。
よく知られたいくつかのSignalsの単純な線形和を提出すると、中和後に直交成分がほとんど残りません。
Signalsを評価するために使用されるターゲットも中和されます。ターゲットは、実質的にはNumerai のカスタムの「特定のリターン」または「残留リターン」です。
中和を実行するために使用されるデータは提供されないため、このプロセスは「ブラックボックス」であることを意味します。 ただし、過去の期間に強いスコアを持つSignalsは、現在のラウンドでも将来のラウンドでも良いスコアが得られない可能性があることに注意すべきです。 Signalsのヒストリカル診断を使用して、中和が将来のSignalsに与える影響を推定することができます。
中和を実装するために使用されているコードはオープンソースです。中和のプロセスについては、このexample notebook で詳しく知ることができます。
あるいは、feature exposure とneutralization のより広い意味合いを理解するために、このフォーラムの投稿をチェックしてみてください。
後続の株式リターンとの相関性が非常に高いSignalsは、Numerai Signalsのスコアが非常に低く、後続の株式リターンとの相関性が弱いSignalsは、高いスコアを出すことができるかもしれません。
言い換えれば、強い予測値を持つ「良い」Signalsは、単独で考えた場合、Numerai Signals のスコアは低いかもしれません。これは、Signalsの重要なユニークな側面を強調しています。 Numerai Signals は、株式のリターンを予測することではなく、Numerai にはない独自のSignalsを見つけることを目的としています。
スコアリングの前に、Signalsは最初に[0, 1]の間でランク付けされ、次に中和されます。最後に、中和されたSignalsとターゲットの間のスピアマン相関を取ることでスコアが計算されます。このスコアは、このドキュメントとウェブサイトでは、単にcorrと呼ばれています。
提出されたSignalsはスコアリング前に中和されます。そうすることで、Signalsとターゲットのデータを規格化し、ターゲットに対するパフォーマンスを向上させることができます。
この操作ではターゲットも中和するため、中和に使用されたデータをNumeraiが提供することはありません。Numeraiは参加者から得られたSignalsを最適化し、最高のパフォーマンスを示すポートフォリオを得ることができます。
例えば、Signalsがカントリーリスクに対して中和されていないデータを提出したとしましょう。 この場合、Numerai Signalsはスコアリングの前にカントリーリスクに対する中和をするので、カントリーリスクの影響はなくなります。そのため、参加者は個々のファクターの影響を気にすることなく独自のSignalsの作成に集中することができます。
ユニバースの一部の銘柄(例:米国株のSignalsのみ)についてのみSignalsを保有している場合でも、Numerai Signalsに参加することができます。Signalsがない銘柄については、Signalsがランク付けされた後、Numerai が自動的に中央値で埋めてくれます。
corrとは、提出したSignalsとNumeraiの保有するSignals(ターゲットは中和済)がどの程度相関しているかを示す指標です。
一方、Meta Model Contribution (MMC)は、提出したSignalsが、Numeraiの保有するSignals(ターゲットは中和済)との相関をとるだけでなく、他の人がNMRをステークしたSignalsとも相関をとり、計算した指標です。
このドキュメントやウェブサイトでは、単にmmcと呼ばれています。
Signalsのmmcは、最初にSignals' Meta Modelと呼ばれる特別なSignalsを構築することによって計算されます。ここで、Signals Meta Modelとは、与えられたラウンドに対してNumerai Signals上のすべての(ランク付けされ、中和された)Signalsのステーク加重平均として定義されたものです。Signalsのmmcは、Signals' Meta Modelに中和された後のターゲットに対するSignalsの相関を表す指標です。
あなたが提出したSignalsが高いMMCを示す場合、他の人が提出したSignalsよりも優位であることを意味します。
MMCはNumerai Tournamentから取った概念であり、スコアリングシステムは非常に似ています。Numerai でのMMCの計算方法の詳細については、Numerai Tournamentのドキュメントのmetamodel contribution のセクションを参照してください。
Numerai SignalsのMMCの計算は、Numerai Tournamentのそれとは完全に分離されていることに注意してください。具体的には、Numerai Signalsへの提出のみがSignalsのメタモデルを構築するために使用されます。
提出したSignalsに自信がある場合、corr または corr_plus_mmc にNMRをステークすることができます。
ステーキングとは、NMRをイーサリアムブロックチェーンのスマートコントラクトに固定することを意味します。NumeraiはロックアップされたNMRに報酬を追加したり、NMRを没収することができます。
あなたはウェブサイトであなたのステーク量を管理できます。ステークを増やすと、NMRはウォレットからステーキングコントラクト(Numeraiの保有しているETHアカウント)に転送されます。ステークを減らすと、NMRは約4週間の遅延後にウォレットに戻されます。また、ステークの種類を変更することもできます。これにより、ステークしたいスコア(Corr,MMC)を決められます。
ステークを作成するには、ウェブサイトの"manage stake"ボタンをクリックし、ステークを増加させるためのリクエストを作成します。ここでは、corrとcorr_plus_mmcのどちらにステークするかを選択することができます。ステークを減らしたい場合は、"change request"を作成し、ステークを減少させることもできます。
change requestsはすぐに反映されません。変更を適用する前に、必ずウェブサイトに表示されている"effective date"を再確認してください。
どれだけのNMRを得られるかはNMRのステーク量と、Corr,MMCの値に依存します。 スコアが高いほど、より多くのNMRを得ることができます。もし負のCorr,MMCとなった場合、ステークしたNMRの一部が没収され、バーンされます。 バーンとはERC-20トークンの持つ機能の一つであり、トークンを永遠に使用できなくする操作のことです。 ペイアウトされるNMRの量はステークした量の±25%に制限されています。 ペイアウトは以下の式で計算されます。 payout = stake_value * payout_factor * (corr * corr_multiplier + mmc * mmc_multiplier) stake_value:ラウンド開始時点の最初の金曜日にステークしたNMRの量 payout_factor:10万NMR以下では1になります。10万NMR以上では以下の図に示す値をとります。Numeraiはペイアウトの上限を決めることで持続的なTournamentの開催を行うことができます。 corr:提出した予測ファイルとターゲットの相関 corr_multiplier:現在は2のみ mmc:提出した予測ファイルとメタモデルの相関 mmc_multiplier:0,0.5,1,2の中で一つ選べる。
ペイアウト計算の例を次に示します。 最初の2つの例は、corr_multiplierの影響を示しています。
3番目の例は、負のスコアがペイアウトに影響を与えるかを示しています。
4番目の例は、ペイアウトがステーク量の±25%に制限されていることを示しています。
スコアは毎日更新されますが、ペイアウトはTournamentの終了日(日本時間の木曜日)にのみ行われます。 提出した予測ファイルがプラスのCorr、MMCを持ち続ける限り、得られるNMRの量は増大します。モデルが52週間、毎週同じ正のスコアを取得すると仮定した場合の支払い予測の例を下図に示します。
Numerai signalsには2種類の日付があります。
data_date - 基礎となる株式市場データに対応する日付です。すべてのdata_dateは、その日の市場の終値を参照しており、時刻は含まれていません。例えば、submissionsのfriday_date列の値はdata_date型です。
effective_date- Numerai Signals で行われるアクションやイベントに対応する日付で、常にUTCで指定された時間を含む場合があります。時間帯や株式市場データの処理に時間がかかるため、data_dateとeffective_dateの間には通常遅延が発生します。特に指定がない限り、本ウェブサイトおよび本文書に記載されている日付はすべて effective_date 型です。
提出、ステーク、スコア、ペイアウトは、見やすいようにグループ化されています。このグループのことを「ラウンド」とよびます。
新しいラウンドは毎週土曜日の18:00 UTCに開始します。データの提出とステークの締め切りは月曜日の14:30 UTCです。遅刻した場合は評価されず、ペイアウトにもカウントされません。締め切り後に行われたステーク量の変更は次のラウンドに適用されます。
提出期限に間に合ったSignalsは評価され、保留中のペイアウト量は金曜日、土曜日、火曜日、水曜日に計算されます。 また、ステークしたNMRは金曜日までロックされます。これは、前のラウンドからのペイアウトと次のラウンドのペイアウトを統合することを意味します。水曜日のスコアとペイアウトは、そのラウンドの最終スコアとペイアウトとなります。
ラウンドのユニバースは、前の金曜日のdata_dateで定義されています。4 日間のスコアリングとペイアウトは、3 日目-2 日目、4 日目-2 日目、5 日目-2 日目、6 日目-2 日目の中和リターンに基づいています。ある日のマーケットクローズから、スコアリングのためにデータが利用可能になるまでには2日のラグがあります。例えば、6日目-2日目の中和リターンは月曜日のマーケットクローズまでですが、このデータが利用可能になるのは水曜日です。
NMRのペイアウトはラウンドごとのパフォーマンスに左右されます。リーダーボードに掲載される評価や順位は20ラウンド分のCorr,MMCの加重平均値を用いています。
助けが必要ですか?
質問、サポート、フィードバックは RocketChat にお願いします!

{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"apigateway:*",
"logs:*",
"s3:List*",
"ecs:*",
"lambda:*",
"ecr:*",
"ec2:*",
"iam:*",
"batch:*",
"s3:*"
],
"Resource": "*"
}
]
}powershell -command "$Script = Invoke-WebRequest 'https://raw.githubusercontent.com/numerai/numerai-cli/master/scripts/setup-win10.ps1'; $ScriptBlock = [ScriptBlock]::Create($Script.Content); Invoke-Command -ScriptBlock $ScriptBlock"docker run hello-worlddocker-machine rm default
docker-machine create -d virtualbox --virtualbox-cpu-count=2 --virtualbox-memory=4096 --virtualbox-disk-size=50000 defaultdocker-machine restart defaultdocker-machine enveval $("C:\Program Files\Docker Toolbox\docker-machine.exe" env)pip3 install numerai-cli --usernumerai copy-example -e tournament-python3
numerai copy-example -e signals-python3 numerai uninstall

























2015年に設立されたNumeraiは、毎週データサイエンスのトーナメントを開催しています。世界中のデータサイエンティストが、難読化されたデータを無料でダウンロードし、株式市場の予測モデルを構築することでトーナメントに参加できます。ダウンロードできるデータは難読化されたいるため、金融の知識がなくても参加することができます。
参加者は、自分の予測に賭け金をかけることでトーナメントに参加できます。良い予測を提出すると、より多くの仮想通貨(NMR)を得ることができ、悪い予測を提出すると、NMRを没収されます。
Numeraiは、メタモデルと呼ばれる参加者のモデルを統合したモデルを構築し、得られたデータを自社のグローバル・エクイティ・ヘッジファンドの取引に反映させています。
参加者は、賭け金の有無にかかわらずトーナメントに参加することができますが、NumeraiはNMRがステークされたモデルのみを使用します。参加者は自分でデータを用意する必要はありませんが、チームから与えられたデータを最適化し、自分の予測を提出することが求められます。
Numeraiのホームページと用語集の読み方
Numeraiに予測を提出する方法
モデル診断の読み方
Numeraiとコミュニティに関連する便利なリンク
NumeraiのホームページのURLは、 です。
Numeraire(NMR)トークン: Numeraireはで、Numeraiへのステーキングに使用されます。
NMRは、Numeraiのトーナメントに参加したり、Numeraiに技術的な貢献をすることで獲得できます。NMRトークンは、Numeraiが構築されているで使用することができます。現在、Erasureプロトコル上のアプリは、Numerai、Numerai Signals、Erasure Bayですが、プロトコルは誰でも構築できるようになっています。
Corr: 提出された予測データとターゲットとの相関係数を表します。
TC: 真の貢献度(TC)は、モデルの予測がNumeraiのメタモデルにとってどれだけ価値があるかを示します。
FNC: Feature neutral correlation (FNC)は、提出した予測データをNumeraiのすべての特徴量に対して中和した後の、ターゲットとの相関係数を表します。
Corr / TC / FNC Rep: Rep(評判)は、過去20ラウンドにおけるその指標の加重平均であり、リーダーボードでユーザーをランク付けするために使用されるものです。Repについての詳細は
ステーク 自分のモデルの予測にどれだけ自信があるかを示すために、NMRをステーク(預入れ+ロック)をします。良い予測を提出した場合、NMRを得ることができます。一方、悪い予測を提出した場合はNMRが没収されます。賭け金の最小値は3NMRです。ステークせずに参加して、自分のモデルがどのようなパフォーマンスを示すかを知ってから、ステークするかどうかを決めることができます。
ペイアウト 賭けたNMRに応じて受け取る報酬。毎週(1ラウンドは4週間)、賭け金の最大25%を獲得または没収されます。ステーキングとペイアウトについての詳細はをご覧ください。
DOCS: ルール、FAQ、新規ユーザーセクションを含むNumeraiのへのリンクです。
CHAT: 告知、一般的な議論、データサイエンスなどのチャンネルを含むチャットスペースです。NumeraiチームはRocketChatに積極的に参加しており、プロフィールにはteamタグが付いています。チームメンバーは主に太平洋時間で活動しています。参加はから。
FORUM: Numerai、データサイエンス、ステイク戦略などに関連する議論のためのスペースです。主にコミュニティ内での情報共有を目的としています。リンクはです。
LEADERBOARD: Numeraiに投稿された予測結果のランキングです。ステーク量、Rep、TCなどでソート可能です。
アカウント: 「ウォレット」「モデル」「設定」「ログアウト」の4つのリンクがあります。
・ウォレット:NMRトークンの入金と出金が行えます。
入金(deposit):ウォレットに登録されているアドレスにNMRトークンを送ることで入金できます。このアドレスに他のトークンを送ることはできません。
出金(withdraw):NMRトークンを自分のNumeraiウォレット以外のアドレスに出金することができます。出金を依頼する前に、出金先の外部アドレスがNMR受け取りに適していることを確認してください。間違ったアドレスに送ったNMRは回収できません。
モデル このページでは、Numeraiに投稿するモデルを追加/削除できます。モデルの追加/削除をするには、「新しいモデルの追加」/「既存のアカウントの吸収」を押してください。 複数モデルのアカウントやアカウントの吸収についてはをご覧ください。
設定: Eメール、パスワード、2段階認証(2FA)、APIキーの設定を行います。
アカウントがNMRを保持しているため、2FAによるセキュリティ強化を推奨します。2FAを使用する場合は、リカバリーコードを保存する必要があります。2FAのデバイスにアクセスできなくなっても、Numeraiはアカウントをリセットしません。
モデル情報: モデルのランキングやCorr・TCのRepなどの情報を掲載しています。ˇのボタンでモデルを切り替えることができます。
データ情報: 最新ラウンドのデータダウンロードリンクと、予測結果のアップロードリンクです。
ステーク: NMRのステーク量を調整できます。ステーク方法には、CorrやTCがあります。Corrではターゲットとの相関関係のみにNMRを賭けることができ、TCでは真の貢献にNMRを賭けることができます。
すぐにでもNumeraiに投稿したいという方は、大会参加者のやのKaggle Notebooks、および公式が発表しているがとても参考になります。
今回の記事では、上記の記事や公式のサンプルモデルから一歩踏み込んだ説明(コードでどこを改善するかなど)をします。本説明により提出プロセスがわかりやすくなり、大会の出場者数が増えることを願っています。
今回紹介したコードは、基本的にGoogle Colab上で実行できます。Runボタンを押すと投稿ファイルが作成されますので、ぜひ使ってみてください。
i) Numeraiデータセットの構造
。
train_int8.parquetはトレーニングデータを格納したcsvファイル、validation_int8.parquetは検証用データを格納したcsvファイルです。
id: 暗号化された株のラベル
era: データが収集された期間のことです。eraが同じであれば、同じ期間にデータが収集されたことを意味します。
feature: ビン化した特徴量。特徴量は5段階にビン化されています。
target: ビン化された教師データ。また、ターゲットも5段階にビン化されています。
ii)データ提出までの流れ
データ読み込み
特徴量エンジニアリング
機械学習
モデルの強さについて
pd.read_parquet("train.parquet") で読み込むことができます。
Numeraiデータセットの特徴量は互いに相関が低く、特徴量エンジニアリングを行わなくてもある程度の結果が得られます。
まず、訓練データを見てみると、大まかにいくつかの種類の特徴量があることがわかります。
これらの特徴の平均値、偏差値、歪度などは有用な特徴です。
メモリに余裕のあるPCであれば、特徴量の差分データや多項式特徴量などを含めると、良い結果が得られます。Google Colabで実行するとクラッシュしてしまうので、コードのみ掲載します。
Kaggleで使われているような特徴量エンジニアリングがNumeraiでもそのまま使えるので、train、val、testのデータを加工ことで、良いCorrやSharpe ratioが得られると思います。Numeraiで良い結果を得るために必要な作業の一つが特徴量エンジニアリングであることに間違いはありません。
Numeraiデータセットに機械学習を適用する際に考慮しなければならないのは
i) どのような機械学習手法を使用するか(LightGBM、XGBoost、ニューラルネットワークなど)
ii) どのようなハイパーパラメータを使用するか
iii) 予測結果をスタックするかどうか などです。
今回は、計算時間を考慮してLightGBMを使用します。訓練データ以外のid、era、data_typeは機械学習には必要ありません。残ったfeature_ ○○を説明変数として、targetを教師データとして学習します。学習したデータを用いて、valに含まれるValidationデータとLiveデータについても予測データを作成します。
i)~iii)を考慮すれば、Corr等の値が改善されるので、この部分もやりこみ要素の要素の一つです。
spearman(numerai_corr), numerai_sharpe, max_drawdownを計算して、Validationデータのモデルの強さを推定することができます。
spearman(numerai_corr), numerai_sharpeは大きいほど良いです。
この中でも特にspearmanの値が大きい(0.025以上が目安)と良いモデルであるとみなせます。
(※Corrだけに注目すると、いろいろな問題が発生する可能性があります。Numeraiに詳しい方とは意見が分かれるところだと思いますが、初めて予測結果を提出する方向けの記事なので、このように表現させてください)
なお、用語の説明は以下の通りです。
spearman(numerai_corr): Correlationの平均値。高ければ高いほど良い(参考は0.022~0.04)
numerai_sharpe: 平均リターンを標準偏差で割った比率。高ければ高いほど良い(目安は1以上)
max_drawdown: 最大資産から落ち込む最大値
中和用のファイルをsubmission_file.csvに書き込みます。このファイルにはidとpredictionのカラムが必要です。
学習用データに含まれる特徴量やExample_model(Numeraiが公式に配布しているサンプルモデル)と自分のモデルを線形回帰させることで、それぞれの特徴量と予測結果の相関を下げつつ、シャープ比を向上させることができます。ただし、やりすぎるとCorrが大きく下がってしまうので、0.3~0.5くらいがいいと思います。どのようなモデルをどれだけ中和するかも一つの検討要素となります。(*中和をしない、というのも選択肢の一つです)
以下では、学習用データに含まれる特徴量に対して中和を行います。得られたファイルをcsvとして出力し、NumeraiのホームページのUpload predictionsから提出すれば完了です。
以下に示す目安はあくまでも一例です。参考程度にとどめてください。事実、以下の指標が悪いものでも上位にランクされるモデルも存在します。
Sharpe Ratio: Validationデータのシャープレシオは1以上が良い結果を得やすいです。
CORR20v2: ValidationデータのCorr平均値が0.025~程度であると良いです。
FNCv3: v3データの特徴量で中和した場合のCorr平均値(あまり参考になりません)
Std. Dev.: 各Eraの予測値とValidationデータの相関の標準偏差(あまり参考になりません)
Feat. Exposure: 特徴量の露出度。特徴量と予測結果のバランスの良さを示す指標です。小さければ小さいほど良いです。
Max Drawdown: -0.05以下を目安としましょう。
Ex. Preds Corr: サンプルモデルとの相関性;値はあまり気にする必要はないです。
に参加することでさらなるヒントやサポートを得られます!
に参加することで、日本人参加者とコミュニケーションがとれます!
データ分析、ヒント、チュートリアルに関する投稿は、をチェックしてください。
【初心者向け】
:
【Numeraiに関する説明・HPの見方等】
:
:
:
:
:
:
:
:
【計算モデル関連】
:
:
:
:
【Corr,MMC関連】
:
:
:
:
【Era selection】
:
【Era boost】
:
【Numerai compute/Numerai api関連】
:
:
:
:
【fireside chat】
:
:
:
:
:
:
【掲示板】
【Advent Calendar】
:
:
:
:
:
:
予測結果が書き込まれたcsvファイルの作成
中和の方法

!pip install -Uqq numerapi
import json
import numerapi
import pandas as pd
from contextlib import redirect_stderr
napi = numerapi.NumerAPI()
# Notebook実行時に大量に出力がでてしまうため抑制
with redirect_stderr(open(os.devnull, 'w')):
napi.download_dataset("v5.0/train.parquet", "train.parquet")
napi.download_dataset("v5.0/live.parquet", "live.parquet")
napi.download_dataset("v5.0/features.json", "features.json")
# 特徴量の選択(今回はmedium特徴量を選択)
feature_set_name = "medium"
feature_metadata = json.load(open("features.json"))
feature_cols = feature_metadata["feature_sets"][feature_set_name]
targets = ["target"]
# データの読み込み
train = pd.read_parquet("train.parquet", columns=feature_cols+targets).dropna()
feature_metadata = json.load(open("features.json"))
for k, v in feature_metadata["feature_sets"].items():
print(k, len(v))
def get_group_stats() -> pd.DataFrame:
df_out = pd.DataFrame()
for group in ["intelligence", "wisdom", "charisma", "dexterity", "strength", "constitution"]:
print(group)
cols = feature_metadata["feature_sets"][group]
train_cols = pd.read_parquet("train.parquet", columns=cols).dropna()
print(train_cols.shape)
train_cols[f"feature_{group}_mean"] = train_cols[cols].mean(axis=1)
train_cols[f"feature_{group}_std"] = train_cols[cols].std(axis=1)
train_cols[f"feature_{group}_skew"] = train_cols[cols].skew(axis=1)
train_cols.drop(cols, axis=1, inplace=True)
df_out = pd.concat([df_out, train_cols], axis=1)
return df_out
train_stats = get_group_stats()from sklearn import preprocessing
# interaction計算する変数
cols = [
feature_metadata["feature_sets"]["dexterity"][6],
feature_metadata["feature_sets"]["charisma"][17],
feature_metadata["feature_sets"]["charisma"][62],
feature_metadata["feature_sets"]["dexterity"][13]
]
targets = ["target"]
# データ読み込み
train = pd.read_parquet("train.parquet", columns=cols+targets).dropna()
# interactionを計算する
interactions = preprocessing.PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
interactions.fit(train[cols], train["target"])
train_interact = pd.DataFrame(interactions.transform(train[cols]), index=train.index).astype(np.int8)
train = pd.concat([train, train_interact],axis=1)import pickle
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import KFold
# データの読み込み
train = pd.read_parquet("train.parquet", columns=feature_cols+targets).dropna()
# 学習
cv = KFold(n_splits=3)
for fold, (trn_idx, val_idx) in enumerate(cv.split(train), start=1):
trn_x = train.iloc[trn_idx, :][feature_cols].values
trn_y = train.iloc[trn_idx, :][target].values
val_x = train.iloc[val_idx, :][feature_cols].values
val_y = train.iloc[val_idx, :][target].values
model = lgb.LGBMRegressor(**params)
model.fit(
trn_x, trn_y,
eval_set=[(val_x, val_y)],
callbacks=[lgb.early_stopping(stopping_rounds=100, verbose=True)],
)
pickle.dump(model, open(f"model.lgb.fold_{fold}.pkl", 'wb'))models = []
# 上で作成したpklを読み込む
for path in glob.glob(f"model.*.pkl"):
models.append(pickle.load(open(path, "rb")))
# Live dataでテストを行う
live = pd.read_parquet("live.parquet")
preds_live = np.zeros(len(live))
for model in models:
preds_live += model.predict(live[feature_cols]) / len(models)
live_features["prediction"] = preds_livedef predict(live_features: pd.DataFrame) -> pd.DataFrame:
def neutralize(df, columns, neutralizers=[], proportion=1.0, normalize=True, era_col="era"):
unique_eras = df[era_col].unique()
computed = []
for u in unique_eras:
df_era = df[df[era_col] == u]
scores = df_era[columns].values
if normalize:
scores2 = []
for x in scores.T:
x = (st.rankdata(x, method='ordinal') - .5) / len(x)
x = st.norm.ppf(x)
scores2.append(x)
scores = np.array(scores2).T
exposures = df_era[neutralizers].values
scores -= proportion * exposures.dot(
np.linalg.pinv(exposures.astype(np.float32)).dot(scores.astype(np.float32)))
scores /= scores.std(ddof=0)
computed.append(scores)
return pd.DataFrame(np.concatenate(computed),
columns=columns,
index=df.index)
# main:
preds_live = np.zeros(len(live_features))
for model in models:
preds_live += model.predict(live_features[feature_cols]) / len(models)
live_features["prediction"] = preds_live
# Feature Neutralization
# Ref: https://qiita.com/NT1123/items/6c0123e960ab43148eb1
live_predictions = neutralize(
live_features,
columns=["prediction"],
neutralizers=feature_cols,
proportion=1.0,
normalize=True,
era_col='era'
).rank(pct=True, method="first")
return live_predictions
models = []
for path in glob.glob(f"model.*.pkl"):
models.append(pickle.load(open(path, "rb")))
# Live dataでテストを行う
live = pd.read_parquet("live.parquet")
live_sub = predict(live)
live_sub.to_csv("submission.csv")